















{kind=link}
As the days go by, there are more benchmarks than ever. It is hard to keep track of every HellaSwag or DS-1000 that comes out. Also, what are they even for? Bunch of cool looking names slapped on top of a benchmark to make them look cooler… Not really.
Other than the zany naming that these benchmarks are given, they serve a very practical and careful purpose. Each of them test the model across a set of tests, to see how well the model performs to the ideal standards. These standards are usually how well they fare as compared to a normal human.
This article will assist you in figuring out what these benchmarks are, and which one is used to test which kind of model, and when?
General Intelligence: Can It actually think?
These benchmarks test how well the AI models emulate the thinking capacity of humans.
1. MMLU – Multitask Language Understanding
MMLU is the baseline “general intelligence exam” for language models. It contains thousands of multiple-choice questions across 60 subjects, with four options per question, covering fields like medicine, law, math, and computer science.
It’s not perfect, but it’s universal. If a model skips MMLU, people immediately ask why? That alone tells you how important it is.
Used in: General-purpose language models (GPT, Claude, Gemini, Llama, Mistral)
Paper: https://arxiv.org/abs/2009.03300
2. HLE – Humanity’s Last Exam
HLE exists to answer a simple question: Can models handle expert-level reasoning without relying on memorization?
The benchmark pulls together extremely difficult questions across mathematics, natural sciences, and humanities. These questions are deliberately filtered to avoid web-searchable facts and common training leakage.
The question composition of the benchmark might be similar to MMLU, but unlike MMLU HLE is designed to test the LLMs to the hilt, which is depicted in this performance metric:
As frontier models began saturating older benchmarks, HLE quickly became the new reference point for pushing the limits!
Used in: Frontier reasoning models and research-grade LLMs (GPT-4, Claude Opus 4.5, Gemini Ultra)
Paper: https://arxiv.org/abs/2501.14249
Mathematical Reasoning: Can It reason procedurally?
Reasoning is what makes humans special i.e. memory and learning are both put into use for inference. These benchmarks test the extent of success when reasoning work is performed by LLMs.
3. GSM8K — Grade School Math (8,000 Problems)
GSM8K tests whether a model can reason step by step through word problems, not just output answers. Think of chain-of-thought, but instead of evaluating based on the final outcome, the entire chain is checked.
It’s simple! But extremely effective, and hard to fake. That’s why it shows up in almost every reasoning-focused evaluation.
Used in: Reasoning-focused language models and chain-of-thought models (GPT-5, PaLM, LLaMA)
Paper: https://arxiv.org/abs/2110.14168
4. MATH – Mathematics Dataset for Advanced Problem Solving
This benchmark raises the ceiling. Problems come from competition-style mathematics and require abstraction, symbolic manipulation, and long reasoning chains.
The inherent difficulty of mathematical problems helps in testing the model’s capabilities. Models that score well on GSM8K but collapse on MATH are immediately exposed.
Used in: Advanced reasoning and mathematical LLMs (Minerva, GPT-4, DeepSeek-Math)
Paper: https://arxiv.org/abs/2103.03874
Software Engineering: Can it replace human coders?
Just kidding. These benchmarks test how well a LLM creates error-free code.
5. HumanEval – Human Evaluation Benchmark for Code Generation
HumanEval is the most cited coding benchmark in existence. It grades models based on how well they write Python functions that pass hidden unit tests. No subjective scoring. Either the code works or it doesn’t.
If you see a coding score in a model card, this is almost always one of them.
Used in: Code generation models (OpenAI Codex, CodeLLaMA, DeepSeek-Coder)
Paper: https://arxiv.org/abs/2107.03374
6. SWE-Bench – Software Engineering Benchmark
SWE-Bench tests real-world engineering, not toy problems.
Models are given actual GitHub issues and must generate patches that fix them inside real repositories. This benchmark matters because it mirrors how people actually want to use coding models.
Used in: Software engineering and agentic coding models (Devin, SWE-Agent, AutoGPT)
Paper: https://arxiv.org/abs/2310.06770
Conversational Ability: Can it behave in a humane manner?
These benchmarks test whether the models are able to work across multiple turns, and how well it fares in contrast to a human.
7. MT-Bench – Multi-Turn Benchmark
MT-Bench evaluates how models behave across multiple conversational turns. It tests coherence, instruction retention, reasoning consistency, and verbosity.
Scores are produced using LLM-as-a-judge, which made MT-Bench scalable enough to become a default chat benchmark.
Used in: Chat-oriented conversational models (ChatGPT, Claude, Gemini)
Paper: https://arxiv.org/abs/2306.05685
8. Chatbot Arena – Human Preference Benchmark
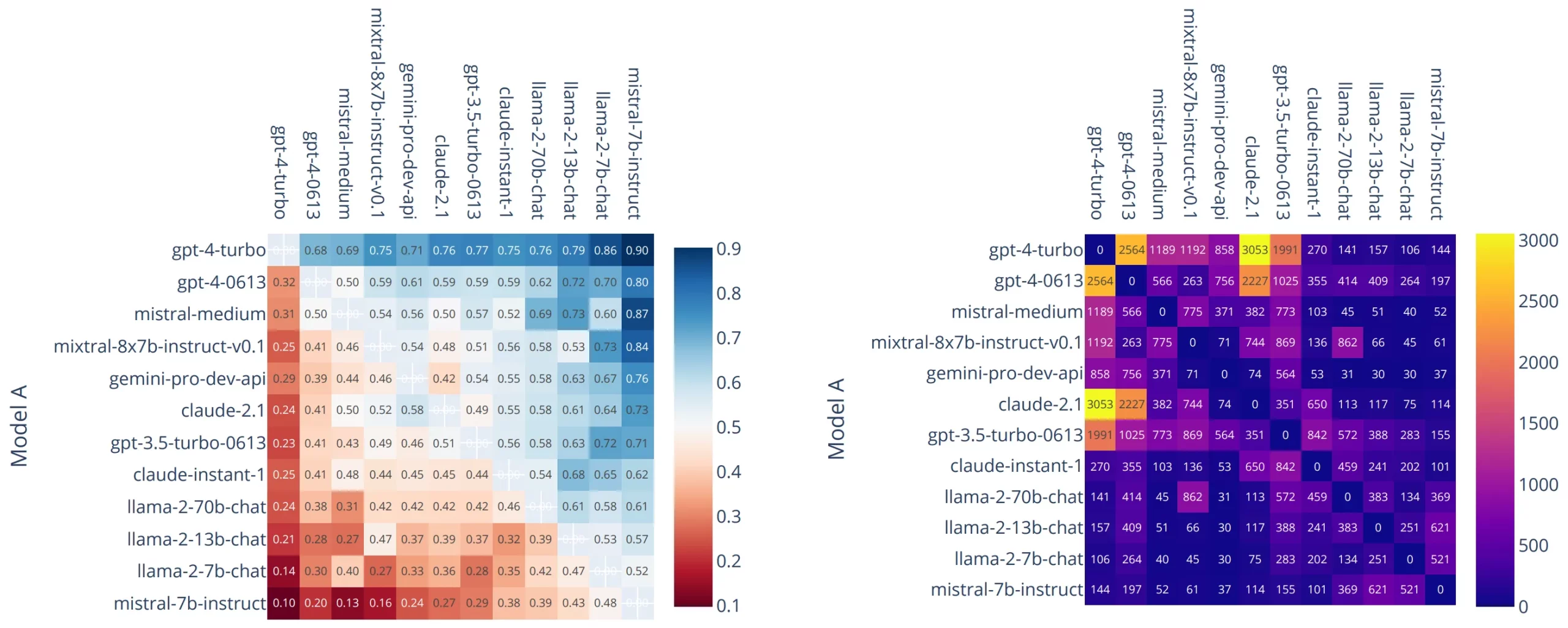
Chatbot Arena sidesteps metrics and lets humans decide.
Models are compared head-to-head in anonymous battles, and users vote on which response they prefer. Rankings are maintained using Elo scores.
Despite noise, this benchmark carries serious weight because it reflects real user preference at scale.
Used in: All major chat models for human preference evaluation (ChatGPT, Claude, Gemini, Grok)
Paper: https://arxiv.org/abs/2403.04132
Information Retrieval: Can it write a blog?
Or more specifically: Can It Find the Right Information When It Matters?
9. BEIR – Benchmarking Information Retrieval
BEIR is the standard benchmark for evaluating retrieval and embedding models.
It aggregates multiple datasets across domains like QA, fact-checking, and scientific retrieval, making it the default reference for RAG pipelines.
Used in: Retrieval models and embedding models (OpenAI text-embedding-3, BERT, E5, GTE)
Paper: https://arxiv.org/abs/2104.08663
10. Needle-in-a-Haystack – Long-Context Recall Test
This benchmark tests whether long-context models actually use their context.
A small but critical fact is buried deep inside a long document. The model must retrieve it correctly. As context windows grew, this became the go-to health check.
Used in: Long-context language models (Claude 3, GPT-4.1, Gemini 2.5)
Reference repo: https://github.com/gkamradt/LLMTest_NeedleInAHaystack
Enhanced Benchmarks
These are just the most popular benchmarks that are used to evaluate LLMs. There are far more from where they came from, and even these have been superseded by enhanced dataset variants like MMLU-Pro, GSM16K etc. But since you now have a sound understanding of what these benchmarks represent, wrapping around enhancements would be easy.
The aforementioned information should be used as a reference for the most commonly used LLM benchmarks.
Frequently Asked Questions
A. They measure how well models perform on tasks like reasoning, coding, and retrieval compared to humans.
A. It is a general intelligence benchmark testing language models across subjects like math, law, medicine, and history.
A. It tests if models can fix real GitHub issues by generating correct code patches.
![]()
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.
Login to continue reading and enjoy expert-curated content.

💸 Earn Instantly With This Task
No fees, no waiting — your earnings could be 1 click away.
Start Earning