















{kind=link}
The AI researcher Andrej Karpathy has developed an educational tool microGPT which provides the easiest access to GPT technology according to his research findings. The project uses 243 lines of Python code which does not need any external dependency to show users the fundamental mathematical principles that govern Large Language Model operations because it removes all complicated features of modern deep learning systems.
Let’s dive into the code and figure out how he was able to achieve such a marvellous feat in such a economical manner.
What Makes MicroGPT Revolutionary?
Most GPT tutorials today rely on PyTorch, TensorFlow, or JAX which serve as powerful frameworks, but they conceal mathematical foundations through their user-friendly interface. Karpathy’s microGPT takes the opposite approach because it builds all of its functions through Python’s built-in modules that include basic programming tools.
The code doesn’t contain the following:
- The code includes neither PyTorch nor TensorFlow.
- The code contains no NumPy or any other numerical libraries.
- The system does not use GPU acceleration or any optimization techniques.
- The code contains no concealed frameworks or unexposed systems.
The code contains the following:
- The system uses pure Python to create autograd which performs automatic differentiation.
- The system includes the complete GPT-2 architecture which features multi-head attention.
- The Adam optimizer has been developed through first principles.
- The system provides a complete training and inference system.
- The system produces operational text generation that generates actual text output.
This system operates as a complete language model which uses actual training data to create logical written content. The system has been designed to prioritize comprehension instead of fast processing speed.
Understanding the Core Components
The Autograd Engine: Building Backpropagation
Automatic differentiation functions as the core component for all neural network frameworks because it enables computers to automatically calculate gradients. Karpathy developed a basic version of PyTorch autograd which he named micrograd that includes only one Value class. The computation uses Value objects to track every number which consists of two components.
- The actual numeric value (data)
- The gradient with respect to the loss (grad)
- Which operation created it (addition, multiplication, etc.)
- How to backpropagate through that operation
Value objects create a computation graph when you use a + b operation or an a * b operation. The system calculates all gradients through chain rule application when you execute loss.backward() command. This PyTorch implementation performs its core functions without any of its optimization and GPU capabilities.
# Let there be an Autograd to apply the chain rule recursively across a computation graph
class Value:
"""Stores a single scalar value and its gradient, as a node in a computation graph."""
def __init__(self, data, children=(), local_grads=()):
self.data = data # scalar value of this node calculated during forward pass
self.grad = 0 # derivative of the loss w.r.t. this node, calculated in backward pass
self._children = children # children of this node in the computation graph
self._local_grads = local_grads # local derivative of this node w.r.t. its children
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data + other.data, (self, other), (1, 1))
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data * other.data, (self, other), (other.data, self.data))
def __pow__(self, other):
return Value(self.data**other, (self,), (other * self.data**(other - 1),))
def log(self):
return Value(math.log(self.data), (self,), (1 / self.data,))
def exp(self):
return Value(math.exp(self.data), (self,), (math.exp(self.data),))
def relu(self):
return Value(max(0, self.data), (self,), (float(self.data > 0),))
def __neg__(self):
return self * -1
def __radd__(self, other):
return self + other
def __sub__(self, other):
return self + (-other)
def __rsub__(self, other):
return other + (-self)
def __rmul__(self, other):
return self * other
def __truediv__(self, other):
return self * other**-1
def __rtruediv__(self, other):
return other * self**-1The GPT Architecture: Transformers Demystified
The model implements a simplified GPT-2 architecture with all the essential transformer components:
- The system uses token embeddings to create vector representations which map each character to its corresponding learned vector.
- The system uses positional embeddings to show the model the exact position of each token in a sequence.
- Multi-head self-attention enables all positions to view prior positions while merging different streams of data.
- The attended information gets processed through feed-forward networks which use learned transformations to analyze the data.
The implementation uses ReLU² (squared ReLU) activation instead of GeLU, and it eliminates bias terms from the entire system, which makes the code easier to understand while maintaining its fundamental elements.
def gpt(token_id, pos_id, keys, values):
tok_emb = state_dict['wte'][token_id] # token embedding
pos_emb = state_dict['wpe'][pos_id] # position embedding
x = [t + p for t, p in zip(tok_emb, pos_emb)] # joint token and position embedding
x = rmsnorm(x)
for li in range(n_layer):
# 1) Multi-head attention block
x_residual = x
x = rmsnorm(x)
q = linear(x, state_dict[f'layer{li}.attn_wq'])
k = linear(x, state_dict[f'layer{li}.attn_wk'])
v = linear(x, state_dict[f'layer{li}.attn_wv'])
keys[li].append(k)
values[li].append(v)
x_attn = []
for h in range(n_head):
hs = h * head_dim
q_h = q[hs:hs + head_dim]
k_h = [ki[hs:hs + head_dim] for ki in keys[li]]
v_h = [vi[hs:hs + head_dim] for vi in values[li]]
attn_logits = [
sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5
for t in range(len(k_h))
]
attn_weights = softmax(attn_logits)
head_out = [
sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h)))
for j in range(head_dim)
]
x_attn.extend(head_out)
x = linear(x_attn, state_dict[f'layer{li}.attn_wo'])
x = [a + b for a, b in zip(x, x_residual)]
# 2) MLP block
x_residual = x
x = rmsnorm(x)
x = linear(x, state_dict[f'layer{li}.mlp_fc1'])
x = [xi.relu() ** 2 for xi in x]
x = linear(x, state_dict[f'layer{li}.mlp_fc2'])
x = [a + b for a, b in zip(x, x_residual)]
logits = linear(x, state_dict['lm_head'])
return logitsThe Training Loop: Learning in Action
The training process is refreshingly straightforward:
- The code processes each dataset document by first converting its text into character ID tokens.
- The code processes each document by first converting its text into character ID tokens and then sending those tokens through the model for processing.
- The system calculates loss through its ability to predict the upcoming character. The system performs backpropagation to obtain gradient values.
- The system uses the Adam optimizer to execute parameter updates.
The Adam optimizer itself is implemented from scratch with proper bias correction and momentum tracking. The optimization algorithm provides complete transparency because all its steps are visible without any hidden processes.
# Repeat in sequence
num_steps = 500 # number of training steps
for step in range(num_steps):
# Take single document, tokenize it, surround it with BOS special token on both sides
doc = docs[step % len(docs)]
tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]
n = min(block_size, len(tokens) - 1)
# Forward the token sequence through the model, building up the computation graph all the way to the loss.
keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]
losses = []
for pos_id in range(n):
token_id, target_id = tokens[pos_id], tokens[pos_id + 1]
logits = gpt(token_id, pos_id, keys, values)
probs = softmax(logits)
loss_t = -probs[target_id].log()
losses.append(loss_t)
loss = (1 / n) * sum(losses) # final average loss over the document sequence. May yours be low.
# Backward the loss, calculating the gradients with respect to all model parameters.
loss.backward()What Makes This a Gamechanger for Learning?
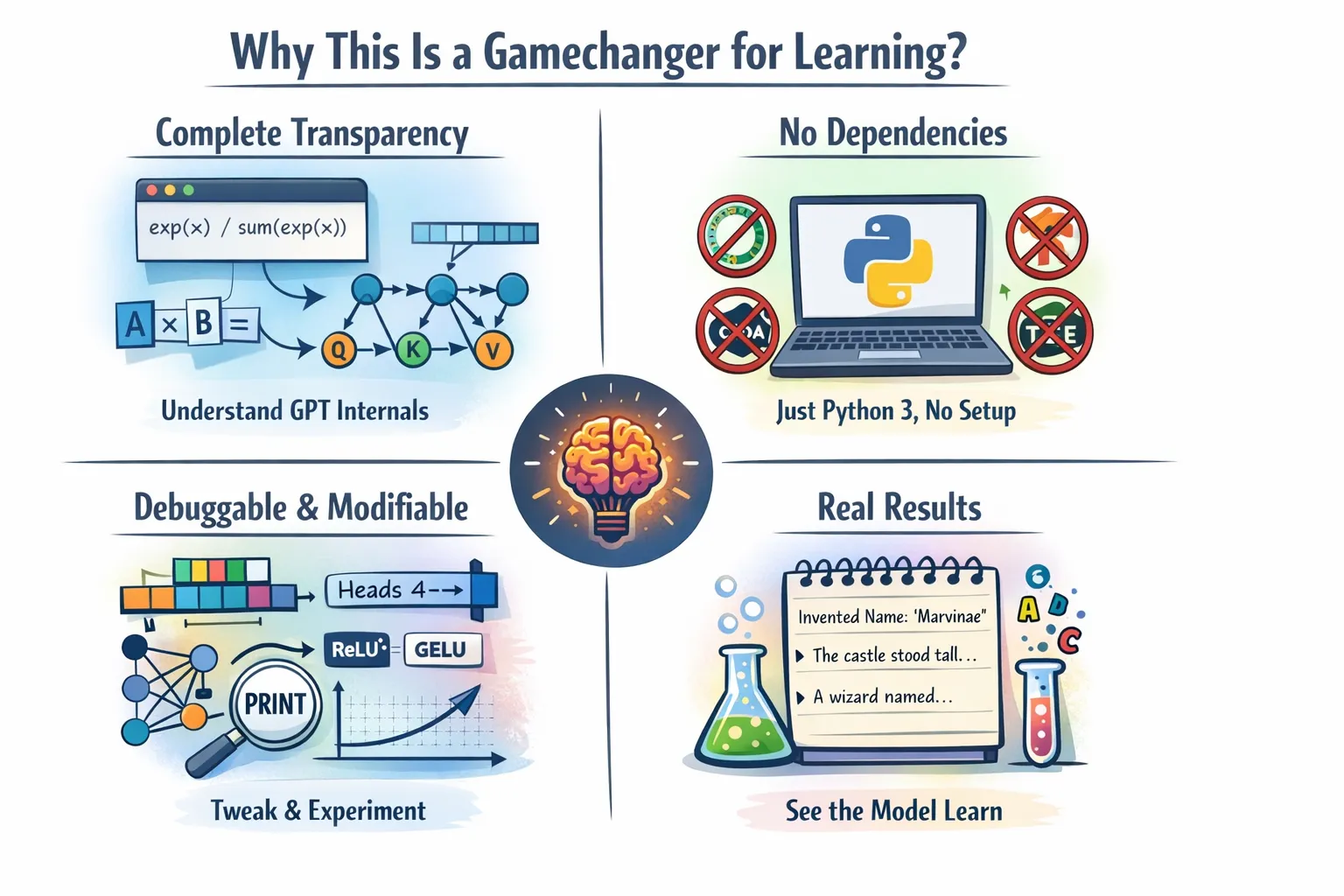
This implementation is pedagogical gold for several reasons:
Complete Transparency
The execution of thousands of lines optimized C++ and CUDA code happens when you use the model.forward() function in PyTorch. The complete set of mathematical calculations appears in Python code which you can read. Want to know exactly how softmax works? How are attention scores calculated? How gradients flow through matrix multiplications? Every detail appears in a transparent manner in the code.
No Dependencies, No Installation Hassles
The system operates without requiring any dependencies while delivering straightforward installation procedures.
No conda environments, no CUDA toolkit, no version conflicts. Just Python 3 and curiosity. You can create a functional GPT training system by copying the code into a file and running it. This removes every barrier between you and understanding.
Debuggable and Modifiable
You can test the system by adjusting its attention head count. You need to replace ReLU² with another activation function. The system lets you add additional layers. The system enables you to change the learning rate schedule through its settings. The entire text can be read and understood by all readers. The system enables you to place print statements at any location throughout the program to observe the exact values which flow through the computation graph.
Real Results
The educational content of this material makes it suitable for learning purposes despite its control deficiencies. The model demonstrates its ability to train successfully while producing understandable text output. The system learns to create realistic names after it has been trained on a name database. The inference section uses temperature-based sampling to show how the model generates creative content.
Getting Started: Running Your Own GPT
The beauty of this project is its simplicity. The project requires you to download the code from the GitHub repository or Karpathy’s website and save it as microgpt.py. You can use the following command for execution.
python microgpt.py It shows the process of downloading training data while training the model and creating text output. The system needs no virtual environments and no pip installations and no configuration files. The system operates through untainted Python which performs unadulterated machine learning tasks.
If you’re interested in the full code, refer to Andrej Kaparthy’s Github repository.
Performance and Practical Limitations
The current implementation shows slow execution because the implemented system takes excessive time to complete its tasks. The training process on a CPU with pure Python requires:
- The system executes operations at a single point in time
- The system performs computations without GPU support
- The system uses pure Python math instead of advanced numerical libraries
The model which trains in seconds with PyTorch requires three hours to complete the training process. The entire system functions as a test environment which lacks actual production code.
The educational code prioritizes clarity for learning purposes instead of achieving fast execution. The process of learning to drive a manual transmission system becomes like learning to drive an automatic transmission system. The process enables you to feel every gear shift while gaining complete knowledge about the transmission system.
Going deeper with Experimental Ideas
The code implementation process requires you to first learn the programming language. The experiments start after you achieve code comprehension:
- Modify the architecture: Add more layers, change embedding dimensions, experiment with different attention heads
- Try different datasets: Train on code snippets, song lyrics, or any text that interests you
- Implement new features: Add dropout, learning rate schedules, or different normalization schemes
- Debug gradient flow: Add logging to see how gradients change during training
- Optimize performance: Test the system with NumPy implementation and basic vectorization implementation while maintaining system performance
The code structure enables users to conduct experiments without difficulty. Your experiments will reveal the fundamental principles that govern transformer functionality.
Conclusion
The 243-line GPT implementation in the name of microGPT developed by Andrej Karpathy functions as more than an algorithm because it demonstrates Ultimate coding excellence. The system shows that understanding transformers requires only a few lines of essential framework code. The system demonstrates that users can understand how attention functions without needing high-cost GPU hardware. Users need only basically building components to develop their language modeling system.
The combination of your curiosity with Python programming and your ability to understand 243 lines of educational code creates your requirements for successful learning. This implementation serves as an actual present for three different groups of people: students, engineers, and researchers who want to learn about neural networks. The system provides you with the most precise view of transformer architecture available across all locations.
Download the file, read the code, make changes or even dismantle the entire process and start your own version. The system will teach you about GPT operation through its pure Python code base, which you will learn one line at a time.
Frequently Asked Questions
A. It is a pure Python GPT implementation that exposes core math and architecture, helping learners understand transformers without relying on heavy frameworks like PyTorch.
A. He implements autograd, the GPT architecture, and the Adam optimizer entirely in Python, showing how training and backpropagation work step by step.
A. It runs on pure Python without GPUs or optimized libraries, prioritizing clarity and education over speed and production performance.
![]()
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]
Login to continue reading and enjoy expert-curated content.

💸 Earn Instantly With This Task
No fees, no waiting — your earnings could be 1 click away.
Start Earning