
















{kind=link}
In the world of Large Language Models (LLMs), speed is the only feature that matters once accuracy is solved. For a human, waiting 1 second for a search result is fine. For an AI agent performing 10 sequential searches to solve a complex task, a 1-second delay per search creates a 10-second lag. This latency kills the user experience.
Exa, the search engine startup formerly known as Metaphor, just released Exa Instant. It is a search model designed to provide the world’s web data to AI agents in under 200ms. For software engineers and data scientists building Retrieval-Augmented Generation (RAG) pipelines, this removes the biggest bottleneck in agentic workflows.
Why Latency is the Enemy of RAG
When you build a RAG application, your system follows a loop: the user asks a question, your system searches the web for context, and the LLM processes that context. If the search step takes 700ms to 1000ms, the total ‘time to first token’ becomes sluggish.
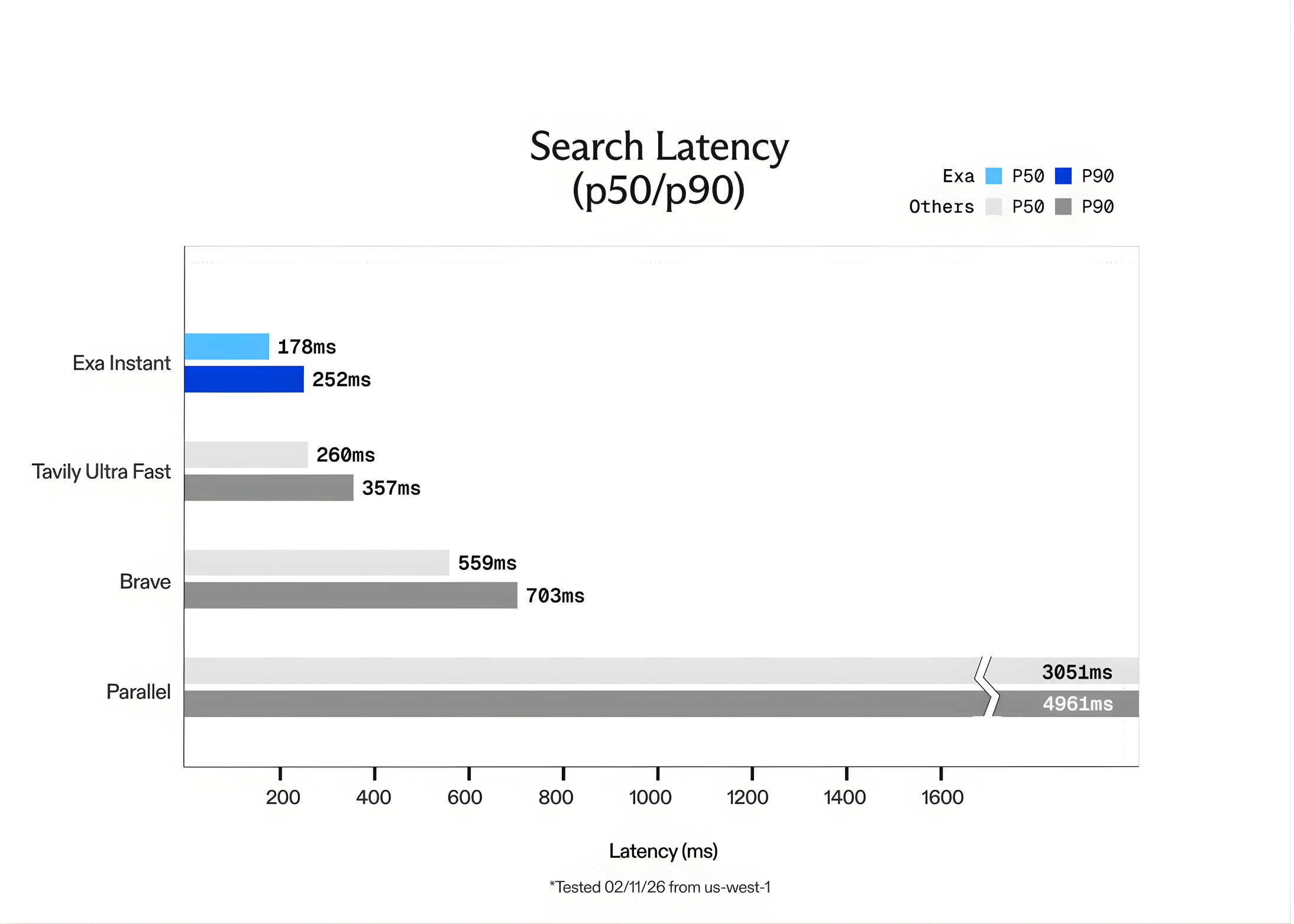
Exa Instant delivers results with a latency between 100ms and 200ms. In tests conducted from the us-west-1 (northern california) region, the network latency was roughly 50ms. This speed allows agents to perform multiple searches in a single ‘thought’ process without the user feeling a delay.
No More ‘Wrapping’ Google
Most search APIs available today are ‘wrappers.’ They send a query to a traditional search engine like Google or Bing, scrape the results, and send them back to you. This adds layers of overhead.
Exa Instant is different. It is built on a proprietary, end-to-end neural search and retrieval stack. Instead of matching keywords, Exa uses embeddings and transformers to understand the meaning of a query. This neural approach ensures the results are relevant to the AI’s intent, not just the specific words used. By owning the entire stack from the crawler to the inference engine, Exa can optimize for speed in ways that ‘wrapper’ APIs cannot.
Benchmarking the Speed
The Exa team benchmarked Exa Instant against other popular options like Tavily Ultra Fast and Brave. To ensure the tests were fair and avoided ‘cached’ results, the team used the SealQA query dataset. They also added random words generated by GPT-5 to each query to force the engine to perform a fresh search every time.
The results showed that Exa Instant is up to 15x faster than competitors. While Exa offers other models like Exa Fast and Exa Auto for higher-quality reasoning, Exa Instant is the clear choice for real-time applications where every millisecond counts.
Pricing and Developer Integration
The transition to Exa Instant is simple. The API is accessible through the dashboard.exa.ai platform.
- Cost: Exa Instant is priced at $5 per 1,000 requests.
- Capacity: It searches the same massive index of the web as Exa’s more powerful models.
- Accuracy: While designed for speed, it maintains high relevance. For specialized entity searches, Exa’s Websets product remains the gold standard, proving to be 20x more correct than Google for complex queries.
The API returns clean content ready for LLMs, removing the need for developers to write custom scraping or HTML cleaning code.
Key Takeaways
- Sub-200ms Latency for Real-Time Agents: Exa Instant is optimized for ‘agentic’ workflows where speed is a bottleneck. By delivering results in under 200ms (and network latency as low as 50ms), it allows AI agents to perform multi-step reasoning and parallel searches without the lag associated with traditional search engines.
- Proprietary Neural Stack vs. ‘Wrappers‘: Unlike many search APIs that simply ‘wrap’ Google or Bing (adding 700ms+ of overhead), Exa Instant is built on a proprietary, end-to-end neural search engine. It uses a custom transformer-based architecture to index and retrieve web data, offering up to 15x faster performance than existing alternatives like Tavily or Brave.
- Cost-Efficient Scaling: The model is designed to make search a ‘primitive’ rather than an expensive luxury. It is priced at $5 per 1,000 requests, allowing developers to integrate real-time web lookups at every step of an agent’s thought process without breaking the budget.
- Semantic Intent over Keywords: Exa Instant leverages embeddings to prioritize the ‘meaning’ of a query rather than exact word matches. This is particularly effective for RAG (Retrieval-Augmented Generation) applications, where finding ‘link-worthy’ content that fits an LLM’s context is more valuable than simple keyword hits.
- Optimized for LLM Consumption: The API provides more than just URLs; it offers clean, parsed HTML, Markdown, and token-efficient highlights. This reduces the need for custom scraping scripts and minimizes the number of tokens the LLM needs to process, further speeding up the entire pipeline.
Check out the Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
