















Turmoil has followed the launch of Claude’s new model. Opus 4.7, the younger sibling of Anthropic’s revolutionary Mythos, is the recent attempt by the company to go public with some of the capabilities of Mythos. Better agentic workflows, better memory, and better real-world tasks than the outgoing model, i.e., the Opus 4.6. That is what was promised on paper. Those who got their hands on it have found the Opus 4.7 vs Opus 4.6 reality to be vastly different.
Both complaints and praises have started flooding in all over social media, making various claims. Out of this mess has risen confusion for most – whether they should switch to Opus 4.7 over 4.6 or not? The answer, in all honesty, is not that simple. Yet, we will try to explore all the sides here and see where we get.
As always, let’s look at what the official statements by Anthropic tell us about this.
Opus 4.7 vs Opus 4.6: What Anthropic Says
First things first, what the company says about the new model vis-à-vis the old one gives us a clear picture of what was originally intended. Only once we know that can we judge if that is even true or not.
So, here is what Anthropic says that is new about the Opus 4.7:
Advanced Software Engineering
As per the official release by Anthropic, Opus 4.7 is built to support long-running, complex software projects. In simpler terms, the model is designed for the “most difficult tasks.” Because of that, Anthropic says users (in its internal tests, mind you) have reported needing less supervision with Opus 4.7 than with Opus 4.6, even on their toughest coding workloads.
There are three clear advantages here that make the Opus 4.7 vs Opus 4.6 shift worth noticing. First, it can handle complicated, time-intensive tasks with more rigor and consistency. In practice, that means you can trust the model more when the work gets messy or layered.
Second, it follows instructions with greater precision, which is important when you want the model to stay within specific rules or workflows. Third, and perhaps most importantly, Opus 4.7 can look for ways to verify its own outputs before responding. That adds a layer of reliability that was not really present in the same way with Opus 4.6.
1. Better Vision
Opus 4.7 also brings a meaningful jump in vision capabilities over Opus 4.6. In simple terms, the new Claude model can process images at a much higher resolution. Anthropic puts that at up to 2,576 pixels on the long edge, or close to 3.75 megapixels. That is more than three times the megapixel count supported by earlier Claude models.
So what does that actually change? Think of tasks like extracting information from dense screenshots, reading detailed charts, or understanding complex diagrams. In those kinds of professional use cases, the Opus 4.7 vs Opus 4.6 improvement could translate into noticeably better accuracy.
2. Improved Real-World Work
In Anthropic’s internal testing, Opus 4.7 performed better than Opus 4.6 across most real-world task categories. For example, it was shown to be a stronger finance analyst, producing more rigorous analyses and models, more polished presentations, and tighter cross-task integration.
Even in third-party evaluations, Opus 4.7 beat the 4.6 model on knowledge work tied to economic value. That improvement showed up across finance, legal work, and other professional domains. This is where the Opus 4.7 vs Opus 4.6 gap starts to feel more practical than technical.
3. Memory
Anthropic also says its latest model is better at using file system-based memory. In other words, Opus 4.7 can retain important notes across long, multi-session work. That matters anytime you are returning to an ongoing task instead of starting from scratch.
The obvious benefit is that you need to provide less context upfront each time you assign the model a new piece of work. Over long projects, that can make the workflow feel much smoother.”
Other than these, there is one bit of information that the company shares, which we should definitely note here:
4. Updated Tokeniser
Opus 4.7 uses an updated tokenizer. Anthropic says that the new one “improves how the model processes text.” But the caveat is that the tokeniser now maps the same input as you used to put in earlier to more tokens. Depending on the content type, there is a roughly 1 to 1.35 times increase.
In addition to this, Opus 4.7 tends to think more than Opus 4.6 at higher effort levels, more so in later turns in agentic settings. This is mainly aimed at increasing the model’s reliability on hard problems. However, again, the downside is an increased production of output tokens.
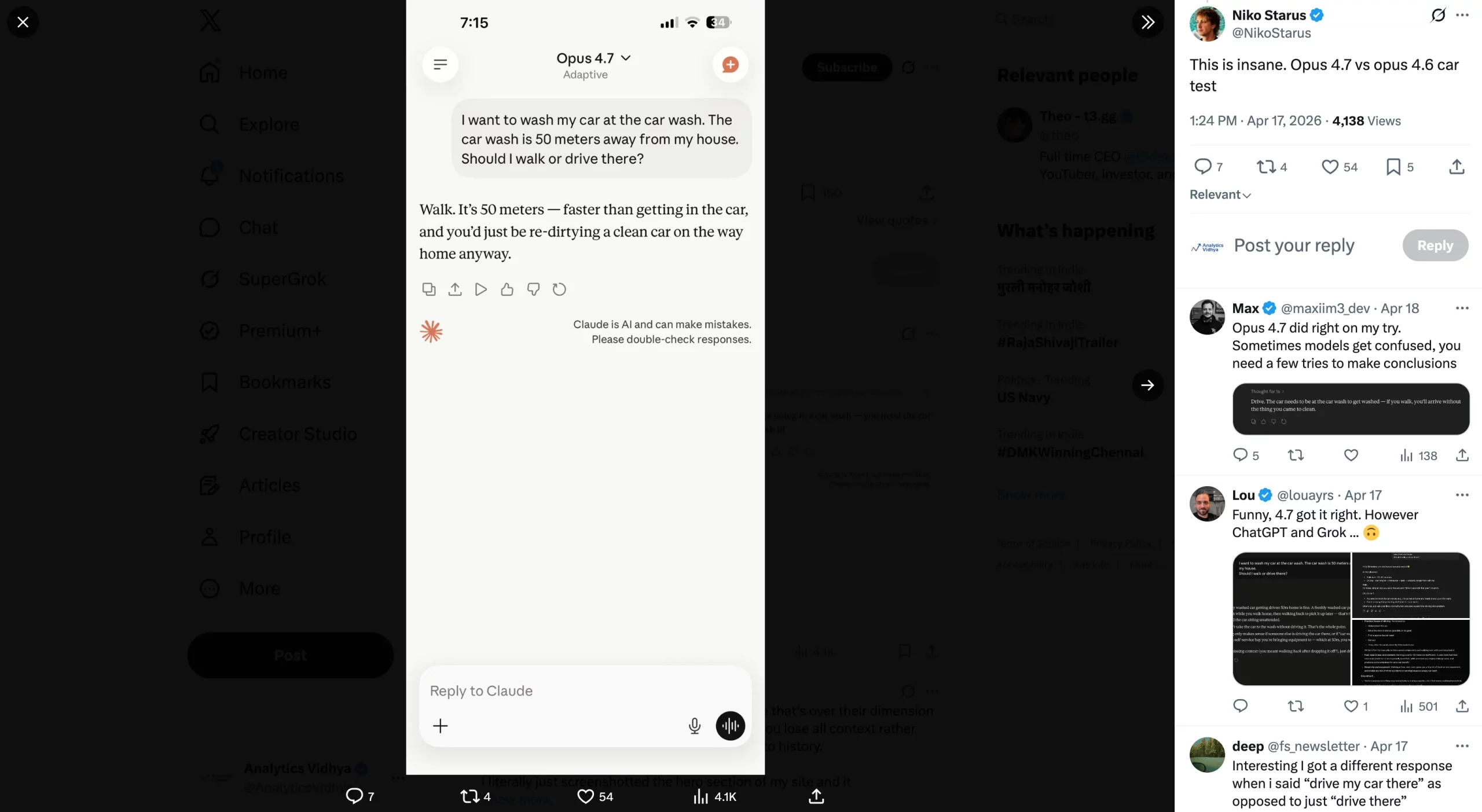
And this is exactly what Claude users have not liked ever since the debut of the Opus 4.7. Which brings us to the flip side of the coin – the user feedback.
Opus 4.7 vs Opus 4.6: What Users Say (BAD)
While the Opus 4.6 was Claude’s shot at fame, outshining even the latest ChatGPT models in daily workflows, several concerns have been raised around the new Opus 4.7. Here I list some of them:
1. Increased Token Use
The pretty obvious one here. Social media is flooded with reports from Claude users spending way more on Opus 4.7 than they used to with Opus 4.6. Since Anthropic has itself confirmed the heightened use of tokens with the new tokenizer, this is not even up for debate. Users are reporting that their session limits are getting over within 3 prompts of use, even with the paid plan of $20/month. I say that’s too much, as my session limit was over with a single prompt.
Though Claude was kind enough to apologise for it. Check it out in the screenshots below:
2. Wastage of Tokens on Reasoning
Just as its token usage has gone up, to add to the misery, the model is supposedly eating up those tokens on worthless justification for its responses too. Users are complaining about lengthy explanations given out by Opus 4.7 on why it can/ can’t perform a specific task. The model has even been found to give out unsolicited commentary on its own boundaries on tasks that Opus 4.6 would easily complete.
3. No Upgrade Whatsoever
Many users have a notion that Opus 4.7 brings no improvements over Opus 4.6 of any kind. Their experience with the model, if not worse (which many report), has not been for the better in any way. These are users who used to love Opus 4.6 and were excited for the upgrade, yet have been left disappointed with the new model’s experience.
Some have even gone far enough to call it “dumber than ever”, while others have started missing Opus 4.6 already. A number of users say that the model is surprisingly similar to Claude Sonnet and is just ‘Sonnet in disguise.’
Check out some of these reactions in the images below.
{kind=link}
4. Ignores Direct Commands
In some of the examples shared on the Internet, users have reported that the latest Claude model completely ignores explicitly written instructions within a prompt. Reddit user @drivetheory, for instance, shares their experience with the Opus 4.7. Having written highly specific instructions on how they want their response to be structured, the new Opus model completely ignored many of the directions within the prompt. This included the configuration requirements, as well as citation needs for the particular answer.
Other than these major ones, there are countless complaints against the new Opus 4.7, most of which have been shared by the existing Claude users who loved Opus 4.6. So, to test out these claims, we ran our own tests on the model.
Let’s Compare Opus 4.7 vs Opus 4.6 on Diverse Tasks
Here is how the new Opus 4.7 performed across tasks.
Here is the task I assigned to Opus 4.7 for this:
“Go through this report by the IMF for India’s Financial System Stability Assessment, and analyse the risks that India’s financial sector faces. Rate these risks based on the most likely ones to impact the sector in the coming years, and give one-line solutions to avert each of these risks completely.”
Opus 4.7 Output:
Opus 4.6 Output:
Observation:
Both models came out with accurate outputs detailing exactly what was asked. Yet, if you look closely, there is a vast difference in how they came to the conclusion and how they both presented it.
Opus 4.7 lays out a complete, detailed plan of 7 steps, executing different steps in the workflow, before it even begins to write the final output. This is exactly what many users are complaining about, as this extended reasoning is also a major reason for the heightened token use during each output. While the model is trying to be as accurate as possible, it breaks down the steps so much that cost efficiency goes out of the window.
And after all this computing, the final output is in a simple text format with one paragraph laid out after another. Accurate, yes, but presentable – no way.
In contrast, Opus 4.6 hardly took 3 steps of execution before it started delivering the final output. What’s more, its output can clearly be seen in a way more presentable format than what Opus 4.7 gave out. Though we didn’t specifically ask it to, it created a new dashboard to present its findings in a more appealing way. You can treat it as deviation, or as extra marks. Your choice.
With almost similar content yet a lot more visual appeal, Opus 4.6 would clearly be my preferred model here.
2. Reasoning
To test its reasoning capabilities, here is the prompt I used:
“You are being evaluated for precision, brevity, and instruction-following.
Task:
A company has 4 project proposals and can fund only 2 of them. Choose the best pair.Projects:
A. Cost: $4M | Expected 3-year return: $8M | Risk of failure: 35% | Strategic value: High | Requires 20 engineers
B. Cost: $3M | Expected 3-year return: $5M | Risk of failure: 15% | Strategic value: Medium | Requires 10 engineers
C. Cost: $5M | Expected 3-year return: $11M | Risk of failure: 45% | Strategic value: Very High | Requires 25 engineers
D. Cost: $2M | Expected 3-year return: $3.5M | Risk of failure: 10% | Strategic value: Low | Requires 6 engineersConstraints:
– Total budget cannot exceed $7M
– Total available engineers = 30
– The company wants at least one “High” or “Very High” strategic value project
– Avoid choosing a pair if both projects have failure risk above 30%Output rules:
1. First line: write only the chosen pair, like “A + B”
2. Second line: write only one sentence of maximum 25 words explaining why
3. Third line: write only “Rejected pairs:” followed by the rejected pairs separated by commas
4. Do not show calculations
5. Do not explain your reasoning
6. Do not add headings, bullet points, or disclaimersImportant:
If you violate any output rule, your answer is incorrect.”
Opus 4.7 Output:
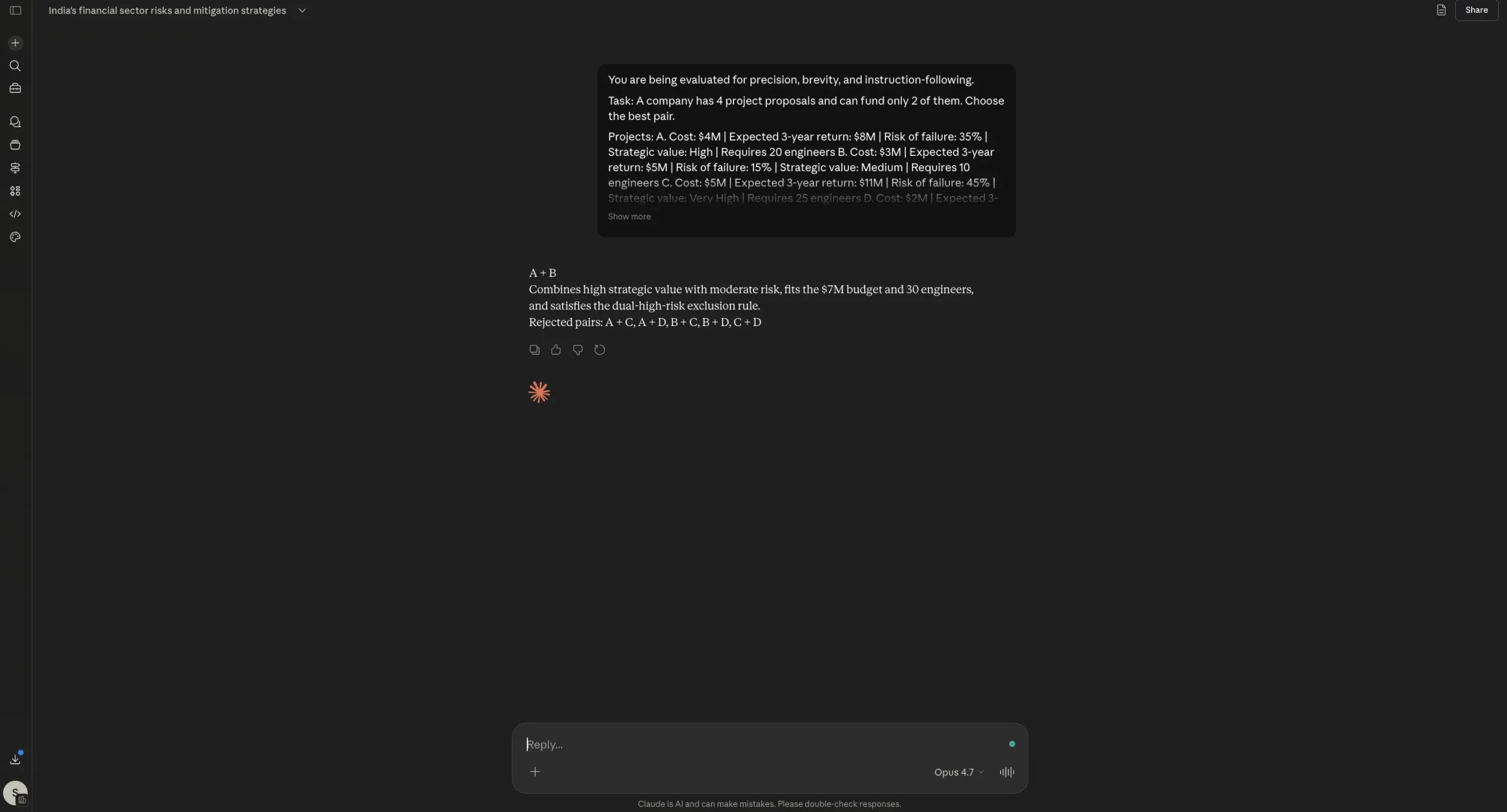
Opus 4.6 Output:
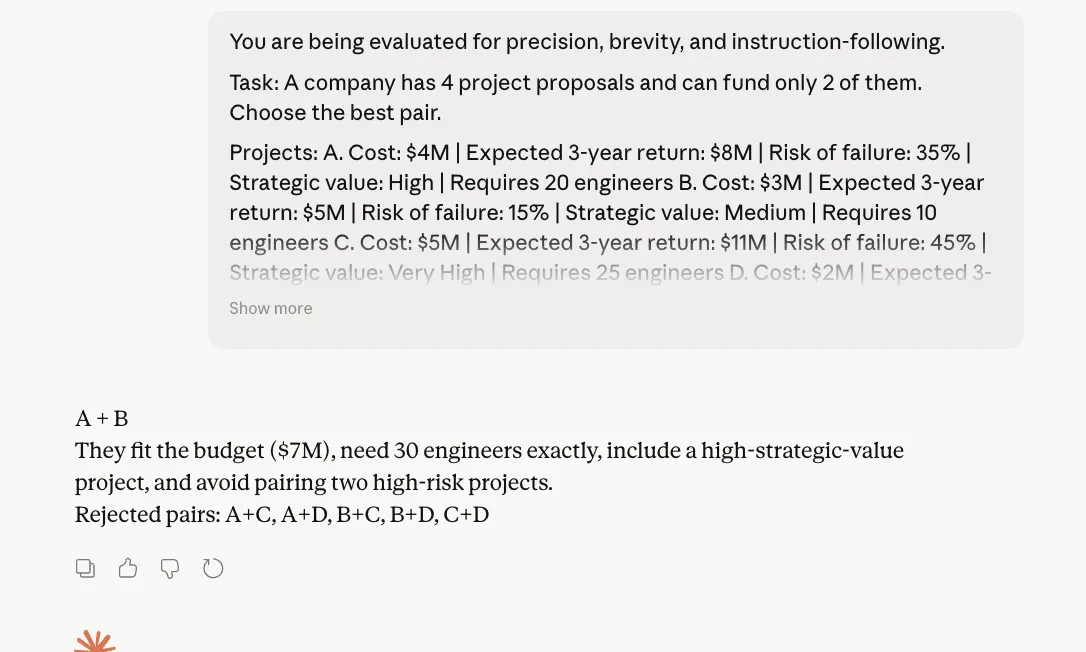
Observation:
In the reasoning test, both Opus 4.6 and Opus 4.7 arrived at the same correct answer, followed the required format, and avoided bloated justification. That is important because this prompt was designed specifically to catch two alleged weaknesses: wasting tokens on reasoning and ignoring direct instructions. Neither model really slipped here. Opus 4.7 stayed within the structure and kept its explanation compact, which is good news for Anthropic. Yet, we can note here that there is no dramatic separation visible from Opus 4.6. In other words, Opus 4.7 does not fail this test, but it also does not prove a clear leap over its predecessor from this result alone.
3. Coding
To test the coding capabilities of the Opus 4.7, here is the prompt I used:
You are being tested for coding precision, instruction-following, and avoiding unnecessary output.
Task:
Fix the Python function below so it returns the length of the longest substring without repeating characters.Buggy code:
def longest_unique_substring(s):
seen = {}
left = 0
best = 0for right in range(len(s)):
if s[right] in seen:
left = seen[s[right]] + 1
seen[s[right]] = right
best = max(best, right – left + 1)return best
Requirements:
1. Return only corrected code
2. Do not explain anything before or after the code
3. Keep the function name unchanged
4. Use the sliding window approach
5. Time complexity must remain O(n)
6. Add exactly 3 test cases as Python assert statements
7. Do not use comments
8. Do not redefine the problem
9. Do not provide alternative solutionsYour answer is wrong if:
– you include any explanation
– you change the function name
– you provide more than 3 asserts
– the code fails on repeated characters that occur before the current window
Opus 4.7 Output:
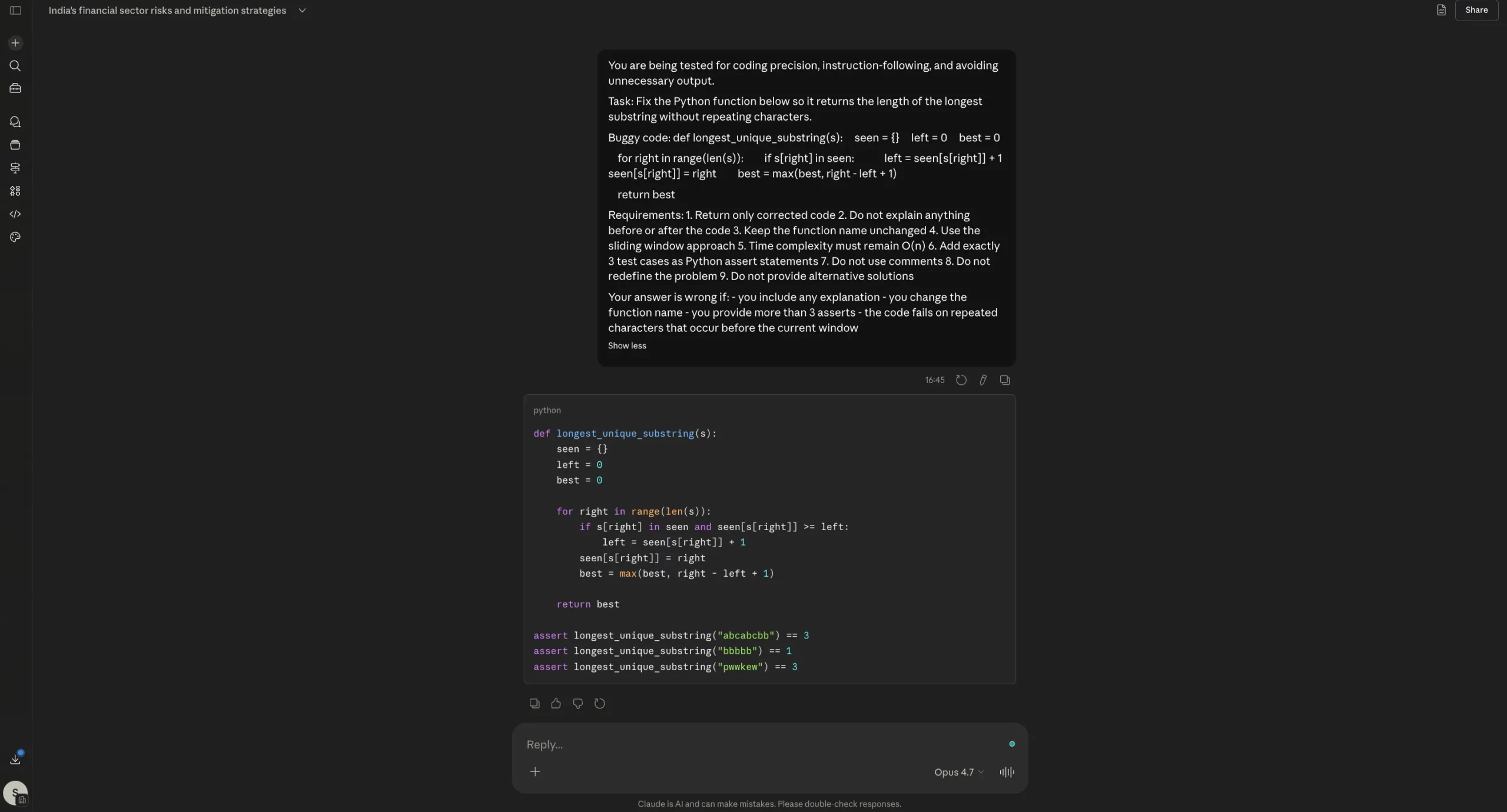
Opus 4.6 Output:
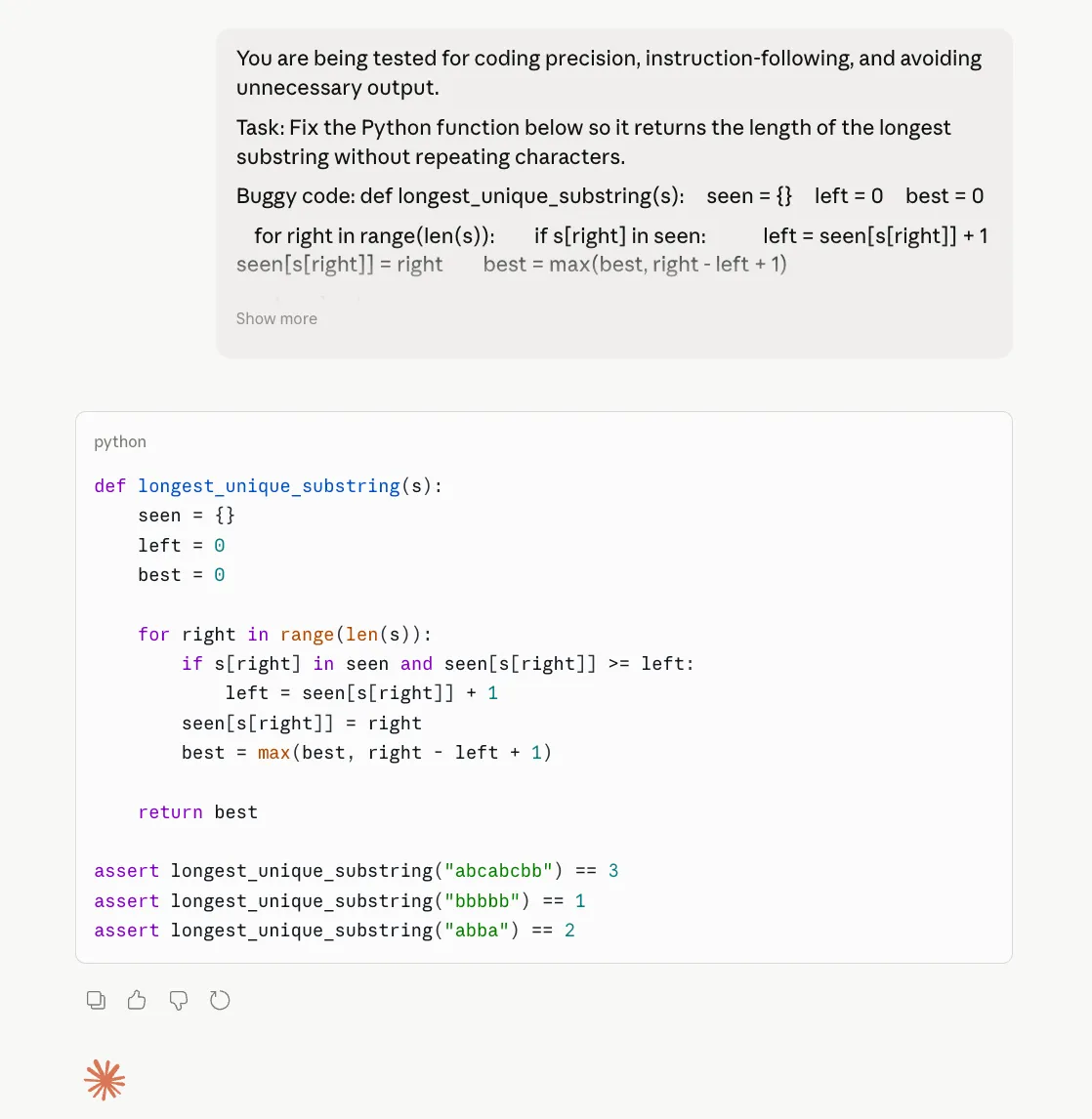
Observation:
On the coding test, both Opus 4.6 and Opus 4.7 did the important thing right: they fixed the bug, returned only the corrected code, kept the same function name, and resisted the temptation to dump extra explanation. That matters because one of the biggest complaints around Opus 4.7 has been wasted tokens and unnecessary commentary. Here, that problem did not really show up. If anything, both models were disciplined. The difference is that Opus 4.7 does not clearly outperform 4.6 in this case. It is correct, yes, but so is 4.6. So this result does not support the claim of a major coding upgrade. It only shows that Opus 4.7 can still behave well on tightly constrained coding tasks.
Final Take: Opus 4.7 vs Opus 4.6
Well, up until now, we have seen what Anthropic says about its all-new Opus 4.7. We have had a look at all the new features it brings to the table, and then many ways in which it is supposedly better than the outgoing model, i.e., the Opus 4.6.
On the flip side, we have also seen the various user experiences that counter these claims. The experiences shared by these users show that the Opus 4.7 is clearly lacking the wow factor that a usual upgrade to such a revered model brings.
And then we put all that to the test in a hands-on experiment of our own, where we put both models side by side for a total of 3 use cases across content extraction and generation, reasoning, and coding. Here is what is clear after a detailed breakthrough so far.
1. Yes, Opus 4.7 uses way more tokens: Well, this is evident from Anthropic’s own accounts as well as from the outcry that has followed the launch of the new model. The very design of the Opus 4.7 makes it eat up tokens more ferociously than ever before.
So, if you are planning to use the model for complex, agentic tasks, my suggestion would be – don’t. At least if you are conscious of your daily limit or API budget. In case the budget is no issue, then feel free to try your hand at the new Opus 4.7 and what it is capable of.
2. Yes, Opus 4.7 performs a lot of iterations unnecessarily: As many users have pointed out, and from what I could figure out from my own use, Opus 4.7 performs way more iterations in its thinking process than necessary, especially so if you compare it to Opus 4.6.
And then when the output is not at par with that of other models, you tend to think of all that compute as a complete waste of time, efforts, and most importantly, tokens.
3. No, Opus 4.7 is not inaccurate: At least in our use with it, the Opus 4.7 did not falter even once, and managed to stick to the instructions quite fantastically, churning out super accurate outputs with all kinds of prompts. So full marks to the model on that front.
Conclusion
Bottom line – definitely give Opus 4.7 a try. But to shift your entire workflow to it, especially when it involves extensive steps and tool calling would be a waste of your tokens I believe. As there is no obvious distinction in the quality of outputs it comes up with, vis-a-vis what Opus 4.6 was capable of.
Login to continue reading and enjoy expert-curated content.

💸 Earn Instantly With This Task
No fees, no waiting — your earnings could be 1 click away.
Start Earning