















{kind=link}
The latest set of open-source models from DeepSeek are here.
While the industry anticipated the dominance of “closed” iterations like GPT-5.5, the arrival of DeepSeek-V4 has ticked the dominance in the favour of open-source AI. By combining a 1.6 trillion parameter MoE architecture with a massive 1 million token context window, DeepSeek-V4 has effectively commoditized high-reasoning intelligence.
This shift is changing the way we think about AI costs and capabilities. Let’s decode the latest variants of DeepSeek family.
What is DeepSeek-V4?
DeepSeek-V4 is the latest iteration of the DeepSeek model family, specifically designed to handle long-context data. It can proccess upto 1 million tokens efficiently making it ideal for tasks such as advanced reasoning, code generation, and document summarization. It utilizes innovative hybrid mechanisms like Manifold-Constrained Hyper-Connections (mHC), allowing it to process over a million tokens efficiently. This makes it a top choice for industries and developers looking to integrate AI into their workflows at scale.
Key Features of DeepSeek-V4
Here are the notable features of DeepSeek’s latest model:
- Open-Source (Apache 2.0): Unlike “closed” models from OpenAI or Google, DeepSeek-V4 is fully open-source. This means the weights and code are available for anyone to download, modify, and run on their own hardware.
- Massive Cost Savings: The API is priced at a fraction of its competitors, roughly 1/5th the cost of GPT-5.5.
- Two Model Variants:
- DeepSeek-V4-Pro: A highly powerful version with 1.6 trillion parameters, designed for high-end computational tasks.
- DeepSeek-V4-Flash: A more efficient, cost-effective version that provides most of the benefits of the Pro version at a reduced price.
| Model | Total Params | Active Params | Pre-trained Tokens | Context Length | Open Source | API Service | WEB/APP Mode |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✔️ | ✔️ | Expert |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✔️ | ✔️ | Instant |
- Unmatched Agentic Capability: Specifically optimized to act as an “Autonomous Agent.” It doesn’t just answer questions; it can navigate your entire project, use tools, and complete multi-step tasks like a digital employee.
- World-Class Reasoning: In math and competitive coding benchmarks, it matches or beats the world’s most powerful private models, proving that open-source can compete at the “Frontier” level.
- Consumer-Hardware Ready: Thanks to extreme efficiency, the V4-Flash version can run on high-end consumer GPUs (like a dual RTX 5090 setup), bringing “GPT-class” performance to your local desk.
DeepSeek-V4: Technical Breakthroughs
DeepSeek-V4 doesn’t just succeed through brute force. It introduces three specific architectural innovations that solve the long context problem:
- Hybrid Attention (CSA + HCA): By combining Compressed Sparse Attention with Heavily Compressed Attention, the model reduces VRAM overhead by 70% compared to standard FlashAttention-2, allowing 1M context lengths to run on consumer-grade enterprise hardware.
- The Muon Optimizer: A revolutionary second-order optimization technique that allows the model to reach “convergence” faster during training, ensuring that the 1.6T parameters are actually utilized efficiently rather than remaining on the config sheet.
Here is how these optimizations help improve the transformer architecture of DeepSeek-V4 as compared to a standard transformer architecture.
| Feature | Standard Transformer | DeepSeek-V4 (2026) |
| Attention Scaling | Quadratic (O(n2)) | Sub-Linear/Hybrid |
| KV Cache Size | 100% (Baseline) | 12% of Baseline |
| Optimization | First-Order (AdamW) | Second-Order (Muon) |
| Prediction | Single-Token | Multi-Token (4-step) |
This architecture essentially makes DeepSeek-V4 a “Reasoning Engine” rather than just a text generator.
This efficiency not only improved the quality of the model responses but also made it affordable!
Economic Disruption: The Price War
The most immediate impact of DeepSeek-V4 is its pricing strategy. It has forced a “race to the bottom” that benefits developers and startups (us).
API Pricing Comparison (USD per 1M Tokens)
| Model | Input (Cache Miss) | Output | Cost Efficiency vs. GPT-5.5 |
| DeepSeek-V4 Flash | $0.14 | $0.28 | ~36x Cheaper |
| GPT-5.5 (Base) | $5.00 | $30.00 | Reference |
DeepSeek’s Cache Hit pricing ($0.028) makes agentic workflows (where the same context is prompted repeatedly) nearly free. This enables perpetual AI agents that can “live” inside a codebase for cents per day.
ChatGPT and Claude users are losing their mind with this pricing! And that too a few hours after the release of GPT 5.5! That clearly sends a message.
And this advantage isn’t limited to the pricing alone. The performance of the DeepSeek V4 clearly puts it in a class of its own.
DeepSeek-V4 vs. The Giants: Benchmarks
While OpenAI and Anthropic have traditionally led in academic reasoning, DeepSeek-V4 has officially closed the gap in applied engineering and agentic autonomy. It isn’t just matching the competition; it’s outperforming them in most scenarios.
1. The Engineering Edge: SWE-bench Verified
This is the gold standard for AI coding. It tests a model’s ability to fix real GitHub issues end-to-end. DeepSeek-V4-Pro has set a new record, particularly in multi-file repository management.
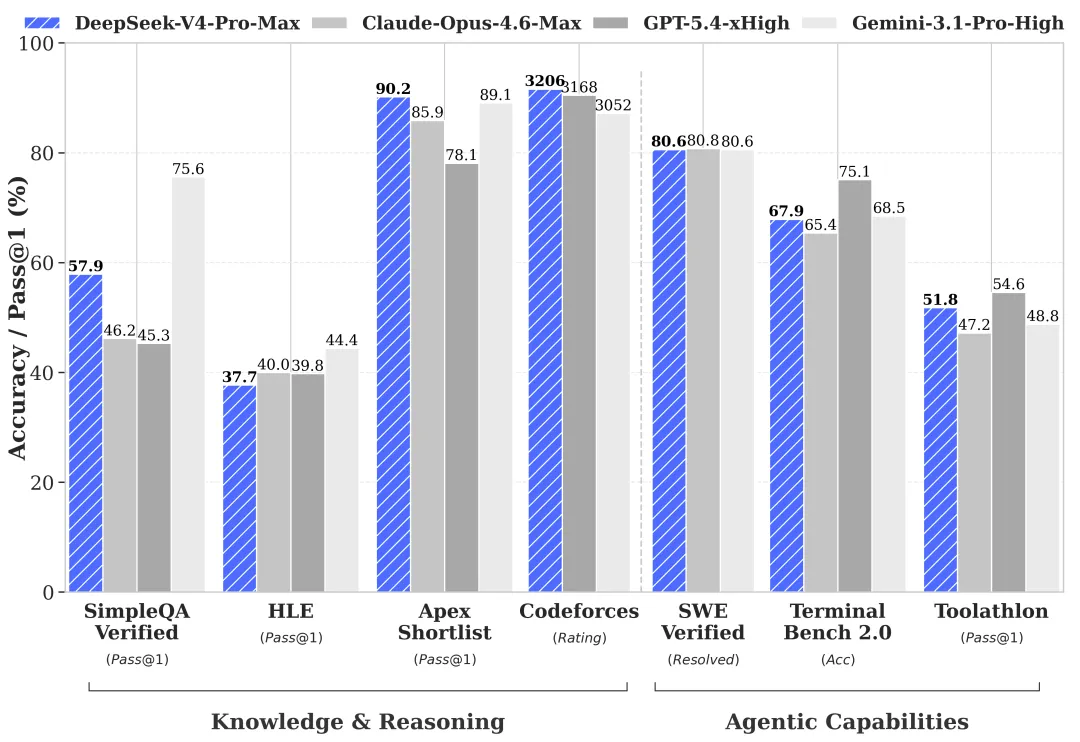
Here is a table outline the performance in contrast to other SOTA models:
| Model | SWE-bench Verified (Score) | Context Reliability (1M Tokens) |
| DeepSeek-V4 Pro | 80.6% | 97.0% (Near-Perfect) |
| GPT-5.5 | 80.8% | 82.5% |
| Gemini 3.1 Pro | 80.6% | 94.0% |
2. Mathematics & Reasoning (AIME / GPQA)
In PhD-level science and competitive math, DeepSeek-V4’s “Thinking Mode” (DeepSeek-Reasoner V4) now trades blows with the most expensive “O-series” models from OpenAI.
- GPQA (PhD-level Science): 91.8% (DeepSeek-V4) vs. 93.2% (GPT-5.5 Pro).
- AIME 2026 (Math): 96.4% (DeepSeek-V4) vs. 95.0% (Claude 4.6).
There is a clear competition in terms of both reasoning and mathematical tasks.
How to Access DeepSeek-V4
You can access DeepSeek-V4 through several methods:
- Web Interface: Access through DeepSeek’s platform at chat.deepseek.com with a simple sign-up and login.
- Cloud Platforms: Use DeepSeek-V4 via cloud-based IDEs or services like HuggingFace spaces.
- Local Deployment: Use services like VLLM which offer DeepSeek-V4 local downloads and usage.
Each method provides different ways to integrate DeepSeek-V4 into your workflow based on your needs. Choose your method and enter the frontier with these new models.
Shaping the Future
DeepSeek-V4 represents the transition of AI from a query-response tool to a persistent collaborator. Its combination of open-source accessibility, unprecedented context depth, and “Flash” pricing makes it the most significant release of 2026. For developers, the message is clear: the bottleneck is no longer the cost of intelligence, but the imagination of the person prompting it.
Frequently Asked Questions
A. Yes, the weights are released under the DeepSeek License, allowing for commercial use with minor restrictions on massive-scale redeployment.
A. DeepSeek-V4 is natively multimodal, but currently it doesn’t support that. The developers claim that It’d be rolled out soon.
A. It utilizes a “distilled” MoE architecture, where only 13B of the 248B parameters are active at any given inference step.
![]()
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.
Login to continue reading and enjoy expert-curated content.

💸 Earn Instantly With This Task
No fees, no waiting — your earnings could be 1 click away.
Start Earning