
















{kind=link}
A new working research from Perplexity and Harvard offers field evidence on what AI agents do to knowledge work. It draws on production data from two Perplexity products: Search and Computer.
The setup is a natural comparison. Search is a conversational answer engine. Computer is an agent that plans and executes tasks end to end. The same users touch both products, so the team can hold the task roughly constant.
What the Study Actually Measures
The research study covers a 90-day window, February 27 through May 27, 2026. Computer launched two days before that window opened.
The core method matches near-identical query pairs across the two products. The research team found 10,000 session pairs with cosine similarity above 0.99. Each pair is effectively the same task attempted both ways.
Computer pairs are gated to sessions that invoke an execution tool. These ‘do’ tools include code execution, browser actions, file writes, and connector calls. That gate ensures every Computer session does real autonomous work.
Adoption rose over the window. Cumulative Computer queries reached 84× their first-week total. A matched analysis found Computer adoption also raised users’ daily Search queries by 1.05. The positive effect points to complementarity, not substitution.

The Cost-Structure Framework
The research grounds its data in a simple task-based model. Each task has a step count, and longer tasks carry weakly higher value.
Agents change the cost structure. They charge a higher fixed cost per task, for delegation and review. But they charge a lower marginal cost per step, since the system executes.
This produces a breakeven step count. Below it, the conversational mode is cheaper. Above it, the agent mode wins. Short lookups stay manual; long workflows move to the agent.
Autonomy: 26 Minutes vs 33 Seconds
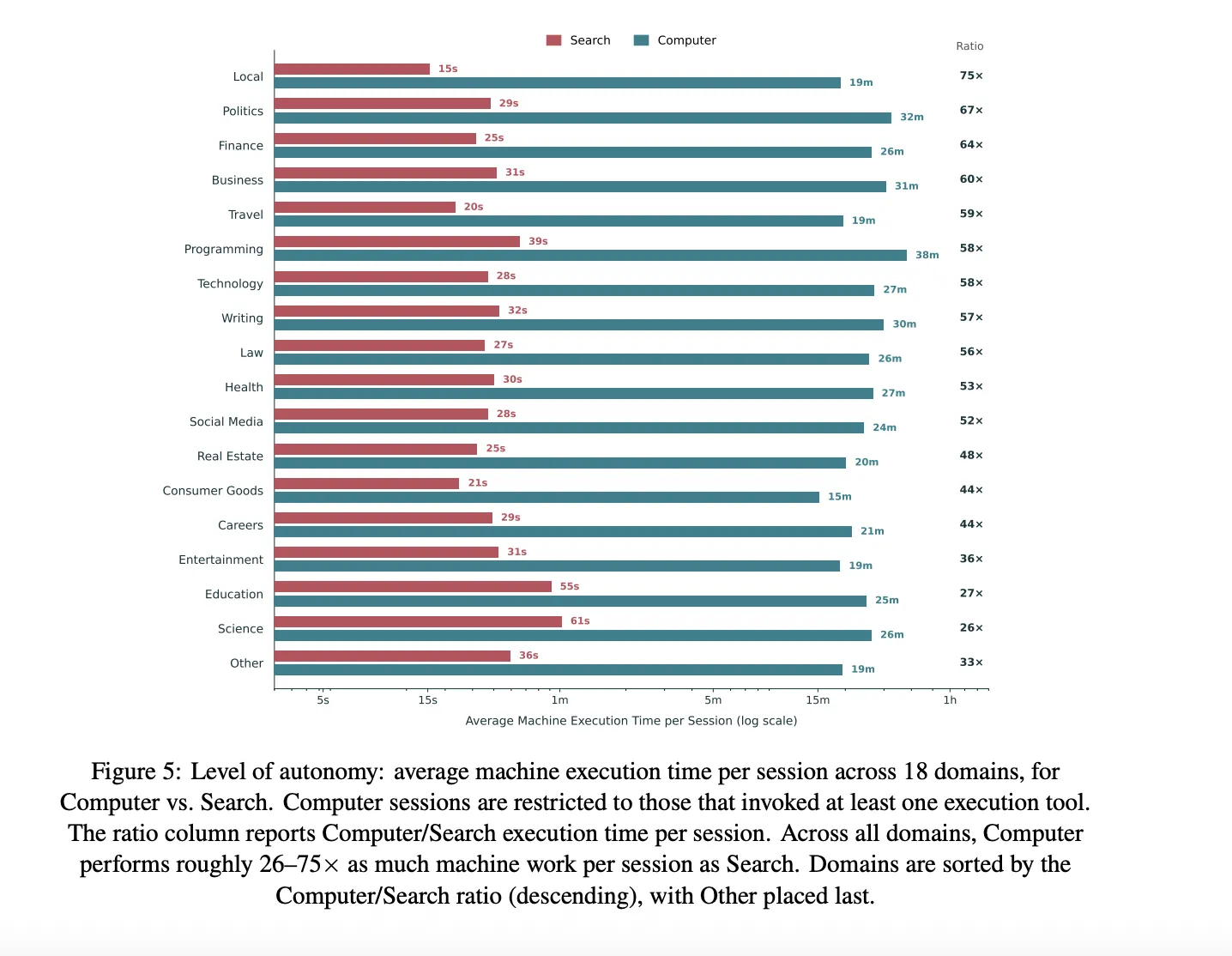
The first autonomy measure is execution time. Computer runs 26 minutes of machine work per session. Search runs 33 seconds. That is a 48× gap.
Medians show the same pattern: 9 minutes versus 14 seconds. The gap varies by domain. Local tasks show 75×; Science shows 26×, since plain answers often suffice.
Higher autonomy did not lower quality here. The research team scored next-turn dissatisfaction from what users do next. Computer’s meaningful dissatisfaction rate was 1.3%, against 2.9% for Search (55% reduction).
Follow-up turns also shift toward review and extension on Computer, though the changes are small. Connector usage rose more clearly. Computer invoked at least one connector in 7.9% of sessions, versus 1.8% for Search. Computer chains external tools that Search users would otherwise run by hand.
Efficiency: Where the Savings Come From
The efficiency section estimates a Search + Human counterfactual. A human with Search alone takes 269 minutes per matched task. Computer + Human takes 36 minutes.
That is 87% less time and 94% less cost overall. Cost savings exceed time savings because domain wages amplify the effect. Computer’s model cost runs $4–10 per task; Search runs about $0.05.
The marginal numbers support the framework. Computer + Human costs $0.16 per step, versus $2.05 for Search + Human. Matched Computer sessions also ran longer prompts, 652 versus 448 characters at the median. That supports the higher fixed-cost assumption for agents.
Breakeven analysis says a professional must finish all manual steps in under 20 minutes to match Computer. The research team cross-checked with an independent LLM estimate and user interviews. The LLM method found 84% time and 93% cost savings. Interviewees reported speedups from 5× to 300×.
Horizontal and Vertical Expansion
Scope is where this research extends past prior work. Autonomy does not just speed up tasks. It changes which tasks users attempt.
Horizontally, Computer queries cross occupational lines more often. Cross-occupation share averaged 59% on Computer, versus 50% on Search. Management and Entrepreneurship showed the largest gap, at 19 points.
Vertically, Computer queries are more demanding. On Bloom’s Revised Taxonomy, 76% required higher-order cognition, versus 55% for Search. Create-level work was 50% of Computer queries, against 26%.
Computer tasks also span more knowledge domains. Each query touched 2.40 O*NET Knowledge domains on average, versus 1.74. It was nearly three times as likely to need three or more domains.
Composability climbs as the O*NET hierarchy gets finer. At the Task Statement level, Computer engaged 60% more activities. About 23% of Computer queries hit a Task Statement that the same users never sent to Search.
Comparison Table: Search vs Computer
| Dimension | Perplexity Search | Perplexity Computer |
|---|---|---|
| Mode in the framework | Conversational answer engine | Agent orchestrator |
| Machine time per session | 33 seconds (median 14s) | 26 minutes (median 9m) |
| Queries per session | 2.8 | 5.3 |
| Meaningful (mid+high) dissatisfaction | 2.9% | 1.3% |
| Sessions with a connector call | 1.8% | 7.9% |
| Counterfactual task time | 269 min (Search + Human) | 36 min (Computer + Human) |
| Cost per step | $2.05 | $0.16 |
| Model cost per task | ~$0.05 | $4–10 |
| Cross-occupation query share | 50% | 59% |
| Higher-order Bloom cognition | 55% | 76% |
| O*NET Knowledge domains per query | 1.74 | 2.40 |
Key Takeaways
- Computer runs 26 minutes of autonomous work per session versus 33 seconds for Search, a 48× gap.
- On matched tasks, Computer + Human cuts estimated time 87% and cost 94% versus Search + Human.
- Computer’s meaningful dissatisfaction rate is 1.3% versus 2.9% for Search, a 55% reduction.
- Computer queries cross occupations more (59% vs 50%) and demand more higher-order cognition (76% vs 55%).
- About 23% of Computer queries hit a Task Statement the same users never sent to Search.
Marktechpost’s Visual Explainer
Research Guide
Harvard × Perplexity
Practitioner-first AI/ML research coverage, decoded for engineers.
Check out the Paper and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
