
















{kind=link}
How do you keep synthetic data fresh and diverse for modern AI models without turning a single orchestration pipeline into the bottleneck? Meta AI researchers introduce Matrix, a decentralized framework where both control and data flow are serialized into messages that move through distributed queues. As LLM training increasingly relies on synthetic conversations, tool traces and reasoning chains, most existing systems still depend on a central controller or domain specific setups, which wastes GPU capacity, adds coordination overhead and limits data diversity. Matrix instead uses peer to peer agent scheduling on a Ray cluster and delivers 2 to 15 times higher token throughput on real workloads while maintaining comparable quality.
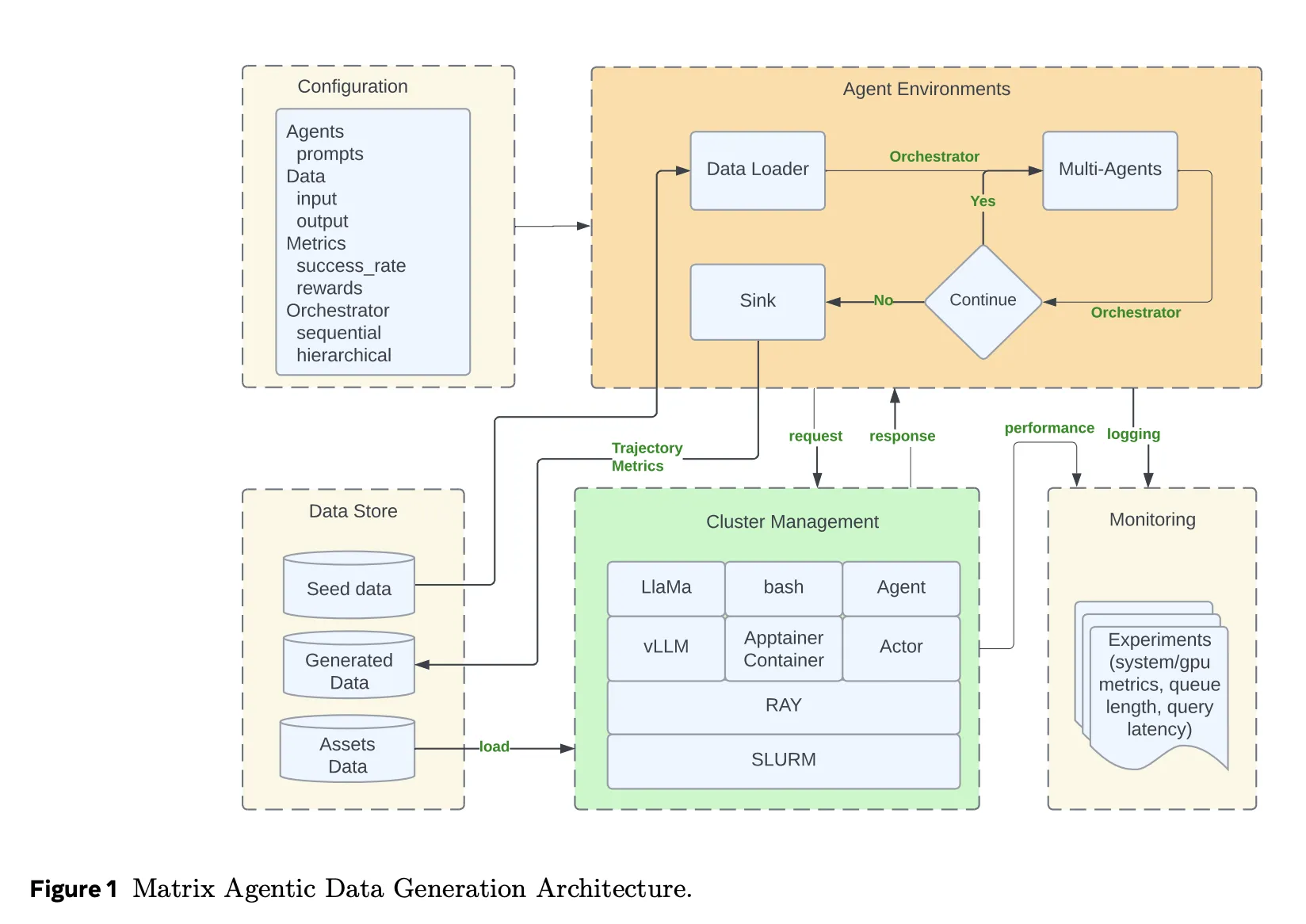
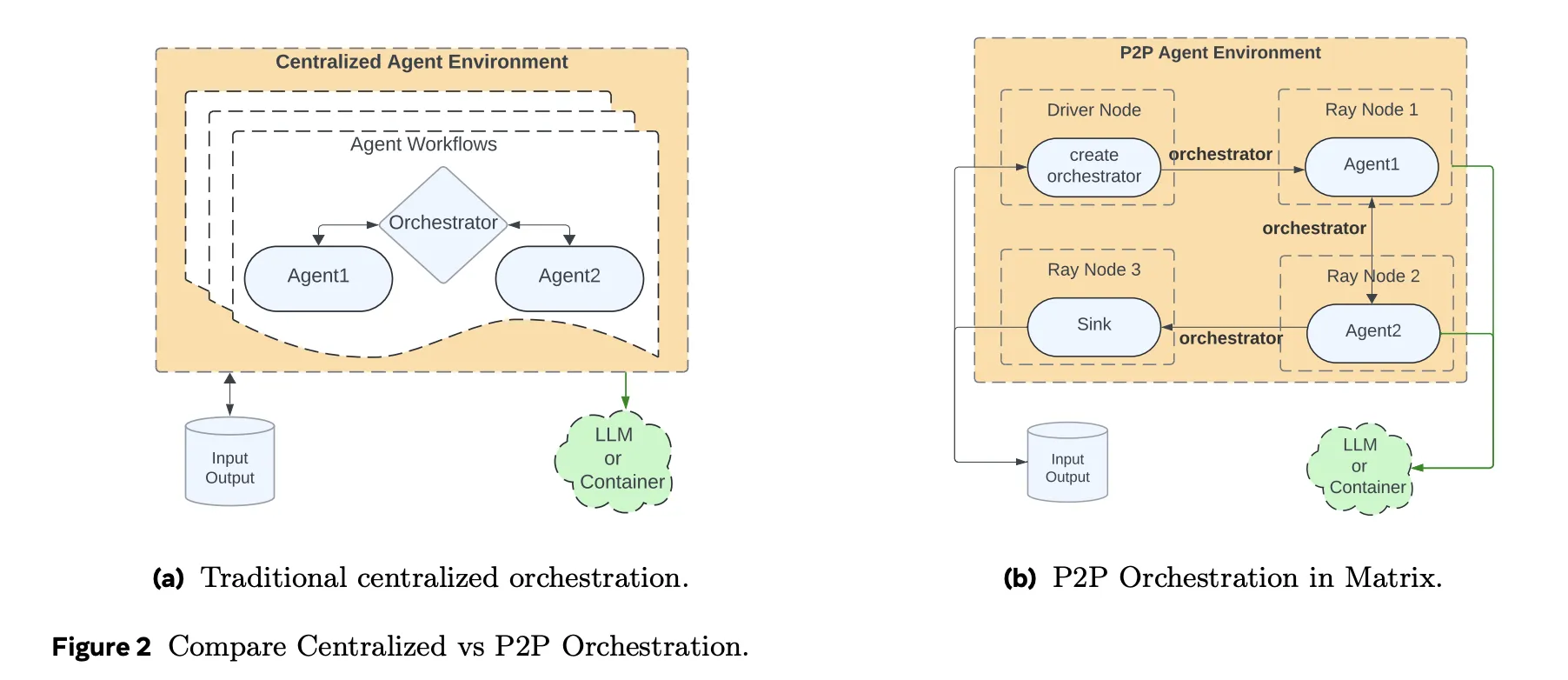
From Centralized Controllers to Peer to Peer Agents
Traditional agent frameworks keep workflow state and control logic inside a central orchestrator. Every agent call, tool call and retry goes through that controller. This model is easy to reason about, but it does not scale well when you need tens of thousands of concurrent synthetic dialogues or tool trajectories.
Matrix takes a different approach. It serializes both control flow and data flow into a message object called an orchestrator. The orchestrator holds the task state, including conversation history, intermediate results and routing logic. Stateless agents, implemented as Ray actors, pull an orchestrator from a distributed queue, apply their role specific logic, update the state and then send it directly to the next agent selected by the orchestrator. There is no central scheduler in the inner loop. Each task advances independently at row level, rather than waiting for batch level barriers as in Spark or Ray Data.
This design reduces idle time when different trajectories have very different lengths. It also makes fault handling local to a task. If one orchestrator fails it does not stall a batch.
System Stack and Services
Matrix runs on a Ray cluster that is usually launched on SLURM. Ray provides distributed actors and queues. Ray Serve exposes LLM endpoints behind vLLM and SGLang, and can also route to external APIs such as Azure OpenAI or Gemini through proxy servers.
Tool calls and other complex services run inside Apptainer containers. This isolates the agent runtime from code execution sandboxes, HTTP tools or custom evaluators. Hydra manages configuration for agent roles, orchestrator types, resource allocations and I or O schemas. Grafana integrates with Ray metrics to track queue length, pending tasks, token throughput and GPU utilization in real time.
Matrix also introduces message offloading. When conversation history grows beyond a size threshold, large payloads are stored in Ray’s object store and only object identifiers are kept in the orchestrator. This reduces cluster bandwidth while still allowing agents to reconstruct prompts when needed.
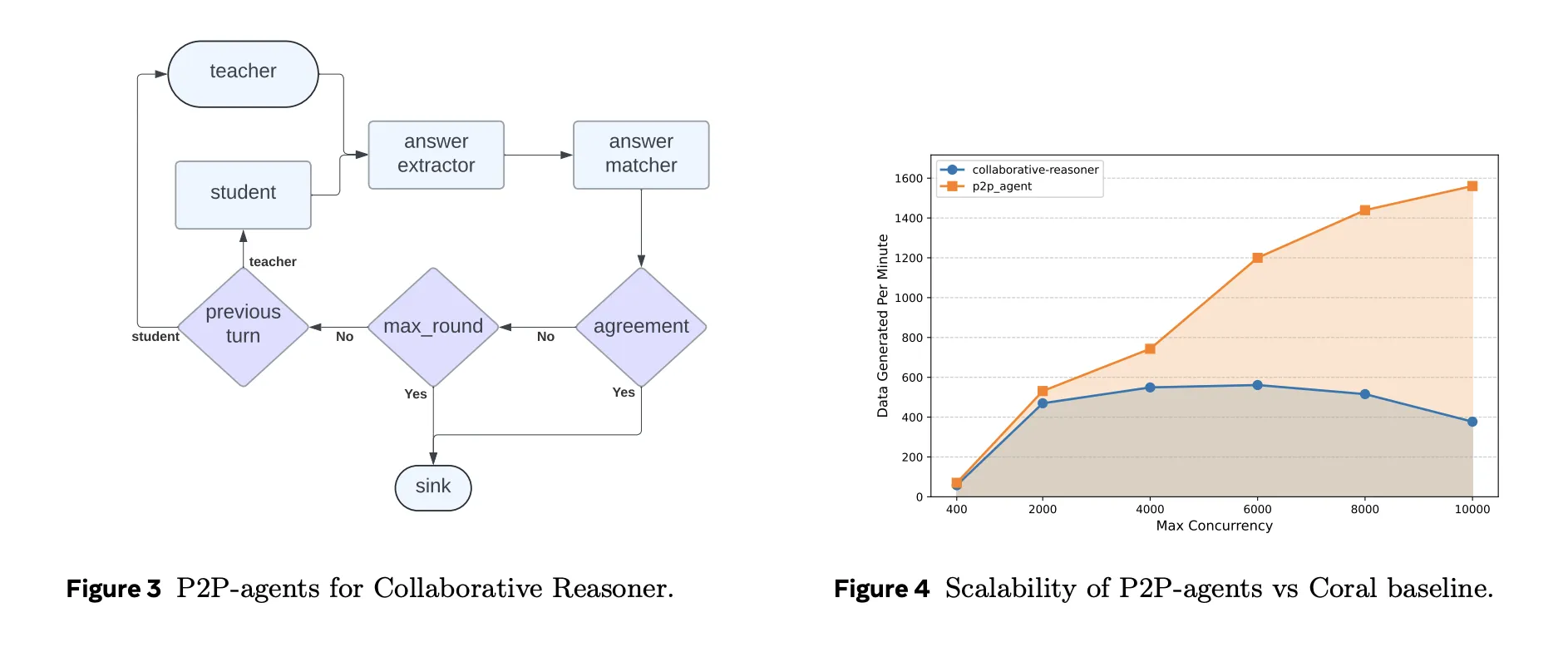
Case Study 1: Collaborative Reasoner
Collaborative Reasoner, also known as Coral, evaluates multi agent dialogue where two LLM agents discuss a question, disagree when needed and reach a final answer. In the original implementation a central controller manages thousands of self collaboration trajectories. Matrix reimplements the same protocol using peer to peer orchestrators and stateless agents.
On 31 A100 nodes, using LLaMA 3.1 8B Instruct, Matrix configures concurrency as 248 GPUs with 50 queries per GPU, so 12,400 concurrent conversations. The Coral baseline runs at its optimal concurrency of 5,000. Under identical hardware, Matrix generates about 2 billion tokens in roughly 4 hours, while Coral produces about 0.62 billion tokens in about 9 hours. That is a 6.8 times increase in token throughput with almost identical agreement correctness around 0.47.
Case Study 2: NaturalReasoning Web Data Curation
NaturalReasoning constructs a reasoning dataset from large web corpora. Matrix models the pipeline with three agents. A Filter agent uses a smaller classifier model to select English passages that likely contain reasoning. A Score agent uses a larger instruction tuned model to assign quality scores. A Question agent extracts questions, answers and reasoning chains.
On 25 million DCLM web documents, only about 5.45 percent survive all filters, yielding around 1.19 million question answer pairs with associated reasoning steps. Matrix then compares different parallelism strategies on a 500 thousand document subset. The best configuration combines data parallelism and task parallelism, with 20 data partitions and 700 concurrent tasks per partition. This achieves about 1.61 times higher throughput than a setting that only scales task concurrency.
Over the full 25 million document run, Matrix reaches 5,853 tokens per second, compared to 2,778 tokens per second for a Ray Data batch baseline with 14,000 concurrent tasks. That corresponds to a 2.1 times throughput gain that comes purely from peer to peer row level scheduling, not from different models.

Case Study 3, Tau2-Bench Tool Use Trajectories
Tau2-Bench evaluates conversational agents that must use tools and a database in a customer support setting. Matrix represents this environment with four agents, a user simulator, an assistant, a tool executor and a reward calculator, plus a sink that collects metrics. Tool APIs and reward logic are reused from the Tau2 reference implementation and are wrapped in containers.
On a cluster with 13 H100 nodes and dozens of LLM replicas, Matrix generates 22,800 trajectories in about 1.25 hours. That corresponds to roughly 41,000 tokens per second. The baseline Tau2-agent implementation on a single node, configured with 500 concurrent threads, reaches about 2,654 tokens per second and 1,519 trajectories. Average reward stays almost unchanged across both systems, which confirms that the speedup does not come from cutting corners in the environment. Overall, Matrix delivers about 15.4 times higher token throughput on this benchmark.

Key Takeaways
- Matrix replaces centralized orchestrators with a peer to peer, message driven agent architecture that treats each task as an independent state machine moving through stateless agents.
- The framework is built entirely on an open source stack, SLURM, Ray, vLLM, SGLang and Apptainer, and scales to tens of thousands of concurrent multi agent workflows for synthetic data generation, benchmarking and data processing.
- Across three case studies, Collaborative Reasoner, NaturalReasoning and Tau2-Bench, Matrix delivers about 2 to 15.4 times higher token throughput than specialized baselines under identical hardware, while maintaining comparable output quality and rewards.
- Matrix offloads large conversation histories to Ray’s object store and keeps only lightweight references in messages, which reduces peak network bandwidth and supports high throughput LLM serving with gRPC based model backends.

Editorial Notes
Matrix is a pragmatic systems contribution that takes multi agent synthetic data generation from bespoke scripts to an operational runtime. By encoding control flow and data flow into orchestrators, then pushing execution into stateless P2P agents on Ray, it cleanly separates scheduling, LLM inference and tools. The case studies on Collaborative Reasoner, NaturalReasoning and Tau2-Bench show that careful systems design, not new model architectures, is now the main lever for scaling synthetic data pipelines.
Check out the Paper and Repo. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.