
















{kind=link}
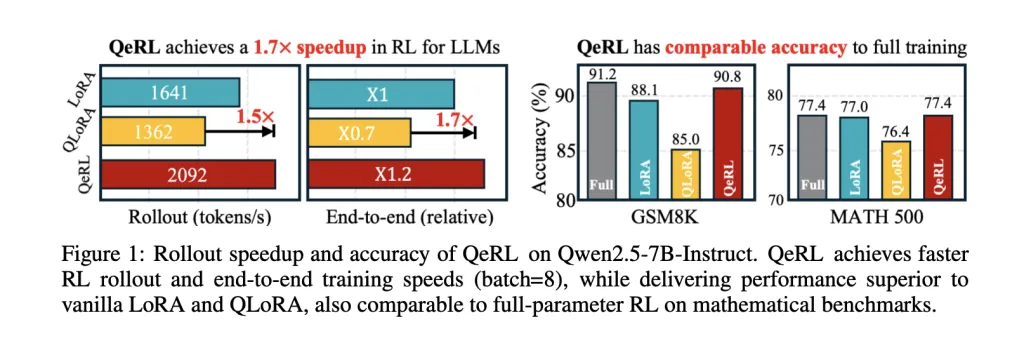
What would you build if you could run Reinforcement Learning (RL) post-training on a 32B LLM in 4-bit NVFP4—on a single H100—with BF16-level accuracy and 1.2–1.5× step speedups? NVIDIA researchers (with collaborators from MIT, HKU, and Tsinghua) have open-sourced QeRL (Quantization-enhanced Reinforcement Learning), a training framework that pushes Reinforcement Learning (RL) post-training into 4-bit FP4 (NVFP4) while keeping gradient math in higher precision via LoRA. The research team reports >1.5× speedups in the rollout phase, ~1.8× end-to-end vs QLoRA in one setting, and the first demonstration of RL training for a 32B policy on a single H100-80GB GPU.
What QeRL changes in the Reinforcement Learning (RL) loop?
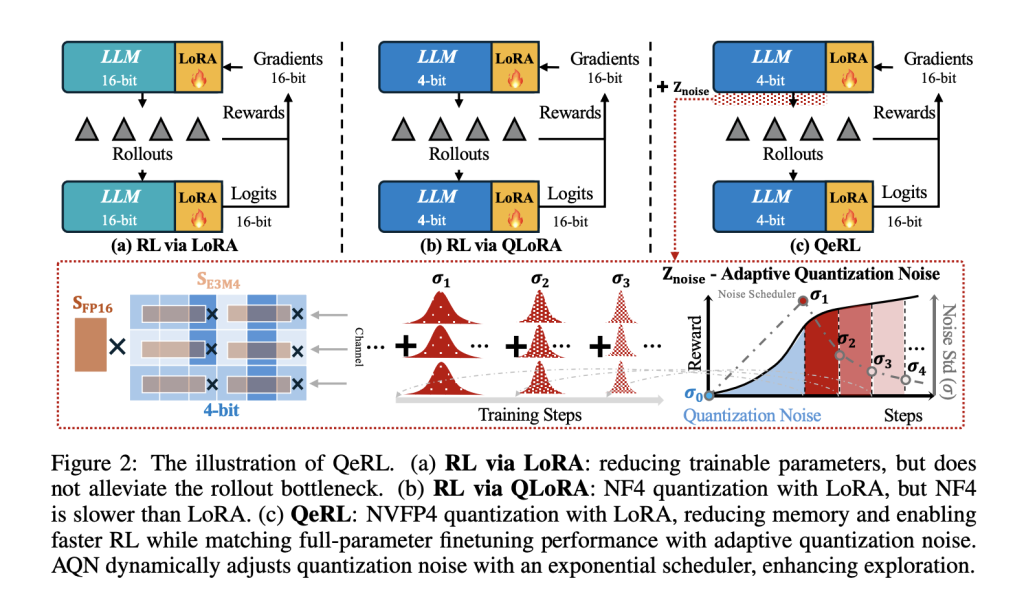
Most RLHF/GRPO/DAPO pipelines spend the bulk of wall-clock time in rollouts (token generation). QeRL shifts the policy’s weight path to NVFP4 (FP4) with dual-level scaling and keeps logits/gradients in higher precision via LoRA, so backprop remains stable while the sampling path hits hardware-efficient FP4×BF16 kernels (Marlin). The result is faster prefill/decoding during rollouts without maintaining a separate full-precision policy.
Mechanically, the research team integrates Marlin-based FP4 kernels in both rollout and prefill, while LoRA limits trainable parameters. This directly targets the stage that dominates RL cost and latency for long reasoning traces.
Quantization as exploration, made schedulable
A core empirical finding: deterministic FP4 quantization raises policy entropy, flattening token distributions early in training and improving exploration versus 16-bit LoRA and NF4-based QLoRA baselines. To control that effect over time, QeRL introduces Adaptive Quantization Noise (AQN)—channel-wise Gaussian perturbations mapped into LayerNorm scale parameters and annealed with an exponential schedule. This keeps kernel fusion intact (no extra weight tensors) while transitioning from exploration to exploitation.
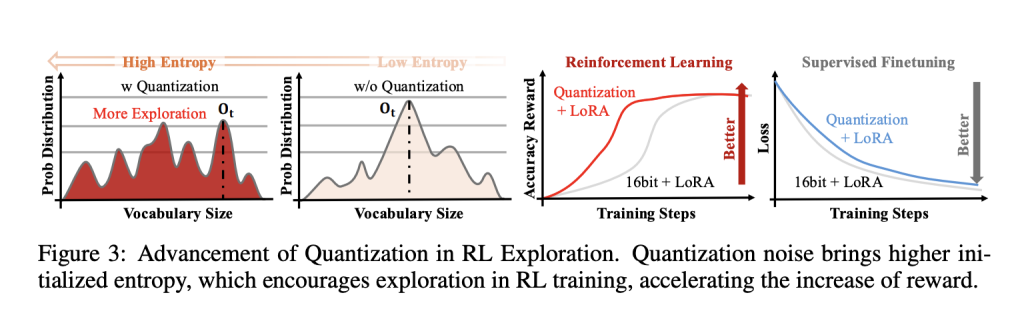
In ablations, QeRL shows faster reward growth and higher final scores on math-reasoning tasks under both GRPO and DAPO, aligning with the hypothesis that structured noise in parameter space can be a useful exploration driver in RL, even though such noise is typically detrimental in supervised fine-tuning.
Reported results
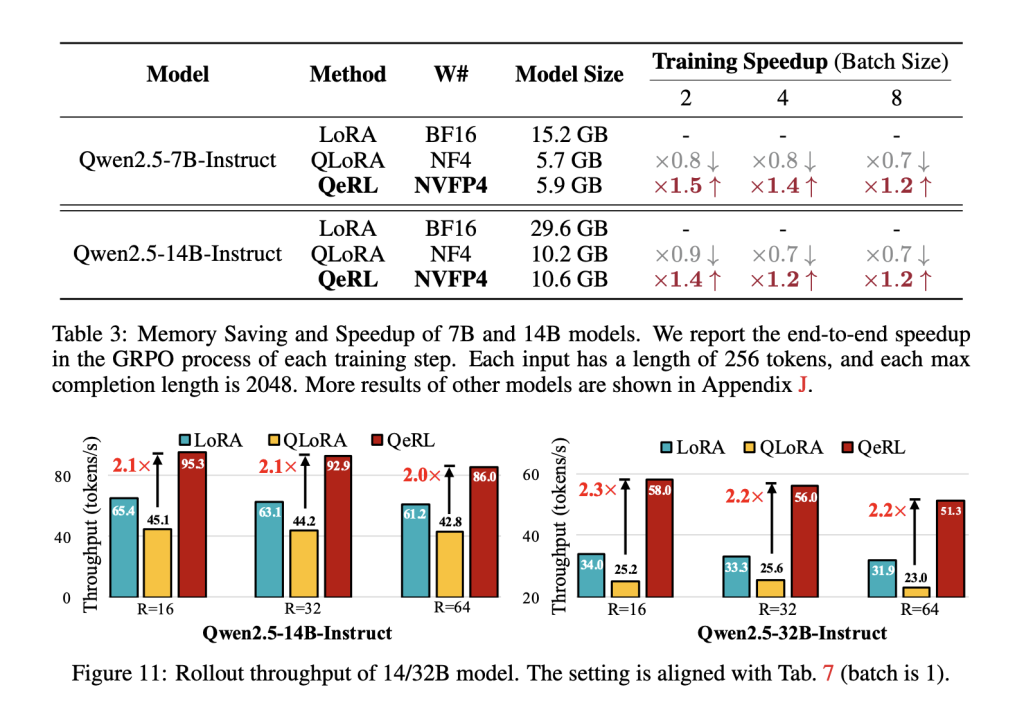
On Qwen2.5 backbone model, the research team show that NVFP4+LoRA outperforms vanilla LoRA and QLoRA in rollout throughput and overall training time, with >2× rollout throughput on 14B/32B models against QLoRA and ~1.8× end-to-end vs QLoRA in a representative setup. They also demonstrate training a 32B policy with GRPO on a single H100-80GB, enabled by the lower memory footprint of weight-only FP4.
Accuracy is competitive with higher-precision baselines. For a 7B model, the research team reports GSM8K = 90.8% and MATH500 = 77.4%, surpassing 16-bit LoRA and QLoRA under their setup and matching full-parameter fine-tuning. Across broader math benchmarks (e.g., BigMath), QeRL maintains parity or advantage, while converging faster due to improved exploration.
What this is—and isn’t?
QeRL is weight-only FP4 with LoRA updates; it does not claim FP4 precision for logits/gradients. The benefits concentrate in rollout/prefill throughput and memory footprint, with empirical evidence that quantization-induced entropy aids RL exploration when AQN modulates it over training. Generalization to modalities beyond math-reasoning tasks or to safety/tool-use RL depends on reward design and sequence lengths.
Key Takeaways
- QeRL combines NVFP4 4-bit weight quantization with LoRA to accelerate the rollout phase and cut memory, enabling RL for a 32B LLM on a single H100-80GB.
- Quantization acts as exploration: FP4 increases policy entropy, while Adaptive Quantization Noise (AQN) schedules channel-wise noise via LayerNorm scales.
- Reported efficiency: >1.5× rollout speedups vs 16-bit LoRA and ~1.8× end-to-end vs QLoRA; >2× rollout throughput vs QLoRA on 14B/32B setups.
- Accuracy holds: Qwen2.5-7B reaches 90.8% on GSM8K and 77.4% on MATH500, matching full-parameter fine-tuning under the paper’s setup.
- NVFP4 is a hardware-optimized 4-bit floating format with two-level scaling (FP8 E4M3 block scalers + FP32 tensor scale), enabling efficient Marlin-based kernels.
QeRL speeds up the RL rollout stage. It quantizes weights to NVFP4 and keeps updates and logits in higher precision using LoRA. It reports >1.5× rollout speedups and can train a 32B policy on a single H100-80GB GPU. It adds Adaptive Quantization Noise to make exploration a controlled signal during training. Results are shown mainly on math-reasoning tasks using GRPO and DAPO. The gains rely on NVFP4 kernel support such as Marlin.
Check out the FULL CODES here and Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.