















{kind=link}
Training a modern large language model (LLM) is not a single step but a carefully orchestrated pipeline that transforms raw data into a reliable, aligned, and deployable intelligent system. At its core lies pretraining, the foundational phase where models learn general language patterns, reasoning structures, and world knowledge from massive text corpora. This is followed by supervised fine-tuning (SFT), where curated datasets shape the model’s behavior toward specific tasks and instructions. To make adaptation more efficient, techniques like LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) enable parameter-efficient fine-tuning without retraining the entire model.
Alignment layers such as RLHF (Reinforcement Learning from Human Feedback) further refine outputs to match human preferences, safety expectations, and usability standards. More recently, reasoning-focused optimizations like GRPO (Group Relative Policy Optimization) have emerged to enhance structured thinking and multi-step problem solving. Finally, all of this culminates in deployment, where models are optimized, scaled, and integrated into real-world systems. Together, these stages form the modern LLM training pipeline—an evolving, multi-layered process that determines not just what a model knows, but how it thinks, behaves, and delivers value in production environments.
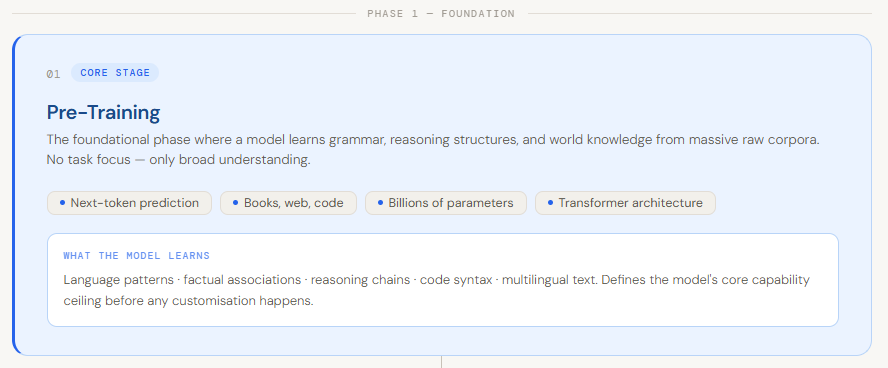
Pre-Training
Pretraining is the first and most foundational stage in building a large language model. It’s where a model learns the basics of language—grammar, context, reasoning patterns, and general world knowledge—by training on massive amounts of raw data like books, websites, and code. Instead of focusing on a specific task, the goal here is broad understanding. The model learns patterns such as predicting the next word in a sentence or filling in missing words, which helps it generate meaningful and coherent text later on. This stage essentially turns a random neural network into something that “understands” language at a general level .
What makes pretraining especially important is that it defines the model’s core capabilities before any customization happens. While later stages like fine-tuning adapt the model for specific use cases, they build on top of what was already learned during pretraining. Even though the exact definition of “pretraining” can vary—sometimes including newer techniques like instruction-based learning or synthetic data—the core idea remains the same: it is the phase where the model develops its fundamental intelligence. Without strong pretraining, everything that follows becomes much less effective.
Supervised Finetuning
Supervised Fine-Tuning (SFT) is the stage where a pre-trained LLM is adapted to perform specific tasks using high-quality, labeled data. Instead of learning from raw, unstructured text like in pretraining, the model is trained on carefully curated input–output pairs that have been validated beforehand. This allows the model to adjust its weights based on the difference between its predictions and the correct answers, helping it align with specific goals, business rules, or communication styles. In simple terms, while pretraining teaches the model how language works, SFT teaches it how to behave in real-world use cases.
This process makes the model more accurate, reliable, and context-aware for a given task. It can incorporate domain-specific knowledge, follow structured instructions, and generate responses that match desired tone or format. For example, a general pre-trained model might respond to a user query like:
“I can’t log into my account. What should I do?” with a short answer like:
“Try resetting your password.”
After supervised fine-tuning with customer support data, the same model could respond with:
“I’m sorry you’re facing this issue. You can try resetting your password using the ‘Forgot Password’ option. If the problem persists, please contact our support team at [email protected]—we’re here to help.”
Here, the model has learned empathy, structure, and helpful guidance from labeled examples. That’s the power of SFT—it transforms a generic language model into a task-specific assistant that behaves exactly the way you want.

LoRA
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning technique designed to adapt large language models without retraining the entire network. Instead of updating all the model’s weights—which is extremely expensive for models with billions of parameters—LoRA freezes the original pre-trained weights and introduces small, trainable “low-rank” matrices into specific layers of the model (typically within the transformer architecture). These matrices learn how to adjust the model’s behavior for a specific task, drastically reducing the number of trainable parameters, GPU memory usage, and training time, while still maintaining strong performance.
This makes LoRA especially useful in real-world scenarios where deploying multiple fully fine-tuned models would be impractical. For example, imagine you want to adapt a large LLM for legal document summarization. With traditional fine-tuning, you would need to retrain billions of parameters. With LoRA, you keep the base model unchanged and only train a small set of additional matrices that “nudge” the model toward legal-specific understanding. So, when given a prompt like:
“Summarize this contract clause…”
A base model might produce a generic summary, but a LoRA-adapted model would generate a more precise, domain-aware response using legal terminology and structure. In essence, LoRA lets you specialize powerful models efficiently—without the heavy cost of full retraining.

QLoRA
QLoRA (Quantized Low-Rank Adaptation) is an extension of LoRA that makes fine-tuning even more memory-efficient by combining low-rank adaptation with model quantization. Instead of keeping the pre-trained model in standard 16-bit or 32-bit precision, QLoRA compresses the model weights down to 4-bit precision. The base model remains frozen in this compressed form, and just like LoRA, small trainable low-rank adapters are added on top. During training, gradients flow through the quantized model into these adapters, allowing the model to learn task-specific behavior while using a fraction of the memory required by traditional fine-tuning.
This approach makes it possible to fine-tune extremely large models—even those with tens of billions of parameters—on a single GPU, which was previously impractical. For example, suppose you want to adapt a 65B parameter model for a chatbot use case. With standard fine-tuning, this would require massive infrastructure. With QLoRA, the model is first compressed to 4-bit, and only the small adapter layers are trained. So, when given a prompt like:
“Explain quantum computing in simple terms”
A base model might give a generic explanation, but a QLoRA-tuned version can provide a more structured, simplified, and instruction-following response—tailored to your dataset—while running efficiently on limited hardware. In short, QLoRA brings large-scale model fine-tuning within reach by dramatically reducing memory usage without sacrificing performance.
RLHF
Reinforcement Learning from Human Feedback (RLHF) is a training stage used to align large language models with human expectations of helpfulness, safety, and quality. After pretraining and supervised fine-tuning, a model may still produce outputs that are technically correct but unhelpful, unsafe, or not aligned with user intent. RLHF addresses this by incorporating human judgment into the training loop—humans review and rank multiple model responses, and this feedback is used to train a reward model. The LLM is then further optimized (commonly using algorithms like PPO) to generate responses that maximize this learned reward, effectively teaching it what humans prefer.
This approach is especially useful for tasks where rules are hard to define mathematically—like being polite, funny, or non-toxic—but easy for humans to evaluate. For example, given a prompt like:
“Tell me a joke about work”
A basic model might generate something awkward or even inappropriate. But after RLHF, the model learns to produce responses that are more engaging, safe, and aligned with human taste. Similarly, for a sensitive query, instead of giving a blunt or risky answer, an RLHF-trained model would respond more responsibly and helpfully. In short, RLHF bridges the gap between raw intelligence and real-world usability by shaping models to behave in ways humans actually value.

Reasoning (GRPO)
Group Relative Policy Optimization (GRPO) is a newer reinforcement learning technique designed specifically to improve reasoning and multi-step problem-solving in large language models. Unlike traditional methods like PPO that evaluate responses individually, GRPO works by generating multiple candidate responses for the same prompt and comparing them within a group. Each response is assigned a reward, and instead of optimizing based on absolute scores, the model learns by understanding which responses are better relative to others. This makes training more efficient and better suited for tasks where quality is subjective—like reasoning, explanations, or step-by-step problem solving.
In practice, GRPO starts with a prompt (often enhanced with instructions like “think step by step”), and the model generates several possible answers. These answers are then scored, and the model updates itself based on which ones performed best within the group. For example, given a prompt like:
“Solve: If a train travels 60 km in 1 hour, how long will it take to travel 180 km?”
A basic model might jump to an answer directly, sometimes incorrectly. But a GRPO-trained model is more likely to produce structured reasoning like:
“Speed = 60 km/h. Time = Distance / Speed = 180 / 60 = 3 hours.”
By repeatedly learning from better reasoning paths within groups, GRPO helps models become more consistent, logical, and reliable in complex tasks—especially where step-by-step thinking matters.

Deployment
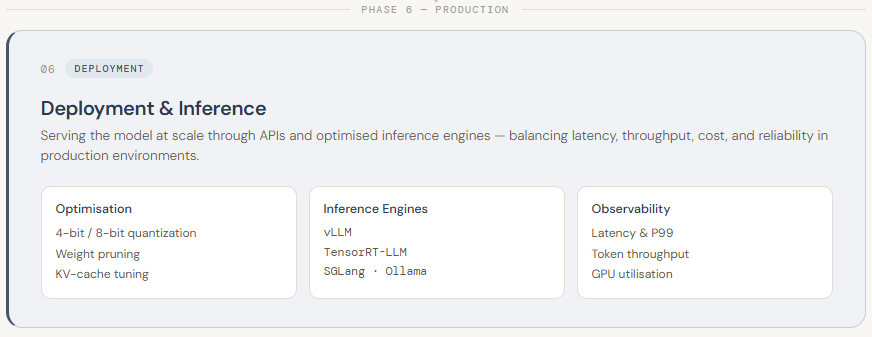
LLM deployment is the final stage of the pipeline, where a trained model is integrated into a real-world environment and made accessible for practical use. This typically involves exposing the model through APIs so applications can interact with it in real time. Unlike earlier stages, deployment is less about training and more about performance, scalability, and reliability. Since LLMs are large and resource-intensive, deploying them requires careful infrastructure planning—such as using high-performance GPUs, managing memory efficiently, and ensuring low-latency responses for users.
To make deployment efficient, several optimization and serving techniques are used. Models are often quantized (e.g., reduced from 16-bit to 4-bit precision) to lower memory usage and speed up inference. Specialized inference engines like vLLM, TensorRT-LLM, and SGLang help maximize throughput and reduce latency. Deployment can be done via cloud-based APIs (like managed services on AWS/GCP) or self-hosted setups using tools such as Ollama or BentoML for more control over privacy and cost. On top of this, systems are built to monitor performance (latency, GPU usage, token throughput) and automatically scale resources based on demand. In essence, deployment is about turning a trained LLM into a fast, reliable, and production-ready system that can serve users at scale.

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.

💸 Earn Instantly With This Task
No fees, no waiting — your earnings could be 1 click away.
Start Earning